
如何使用 Cloud Data Fusion 的无代码方法将数据加载到 BQ
Data Fusion 是一种完全托管的、云原生的企业数据集成服务,用于快速构建和管理免代码数据管道。Data Fusion 的 Web UI 允许构建可扩展的数据集成解决方案来清理、准备、混合、传输和转换数据,而无需管理底层基础架构。它与 Google Cloud 的集成确保了数据可立即用于分析。
Data Fusion 为批处理和实时处理提供了大量预构建的插件。这些可定制的模块可用于扩展 Data Fusion 的本机功能,并且可以通过 Data Fusion Hub 组件轻松安装。
下面我们将介绍使用将 Salesforce 数据转移到 BigQuery 中的不同方法。
常见的数据摄取模式:
为了方便更好的理解,这里有一个常见的说明性用例:
- 客户、潜在客户以及 Salesforce 对象在使用 SalesForce 应用程序时经常由呼叫中心代理操作;
- 需要使用批处理或流式方法识别对这些对象的更改并将其增量加载到数据仓库解决方案中;
- 完全托管和云原生的企业数据集成服务是快速构建和管理无代码数据管道的首选;
- 业务绩效仪表板是通过加入 Salesforce 和数据仓库中可用的其他相关数据来创建的;
使用 Cloud Data Fusion
为了解决上述 Salesforce ETL(提取、转换和加载)场景,我们将演示 Cloud Data Fusion 作为数据集成工具的用法。对于 Salesforce 源对象,通常可以使用以下预构建插件:
- Batch Single Source - 从 Salesforce 读取一个 sObject。可以使用 SQL 查询(Salesforce 对象查询语言查询)或使用 sObject 名称读取数据。我们可以传递增量/范围日期过滤器,还可以指定主键分块参数。sObject 的示例包括机会、联系人、客户、潜在客户以及任何自定义对象;
- 批量多源- 从 Salesforce 读取多个 sObject,通常应该与 multi-sinks 结合使用;
- 流源- 跟踪 Salesforce sObjects 中的更新;
如果这些预构建插件还不能满足需求,那么我们可以使用 Cloud Data Fusion 的插件 API来构建自定义插件。
下面我们将利用开箱即用的 Data Fusion 插件来演示批处理和流式 Salesforce 管道选项。
批处理增量流水线
有许多不同的方法来实现批量增量逻辑。Salesforce 批处理多源插件具有 Last Modified After、Last Modified Before、Duration 和 Offset 等参数,可用于控制增量加载。下面是 Salesforce 对象 Lead、Contact 和 Account 的示例 Data Fusion 批处理增量管道。管道使用之前的开始/结束时间作为增量加载的指南。
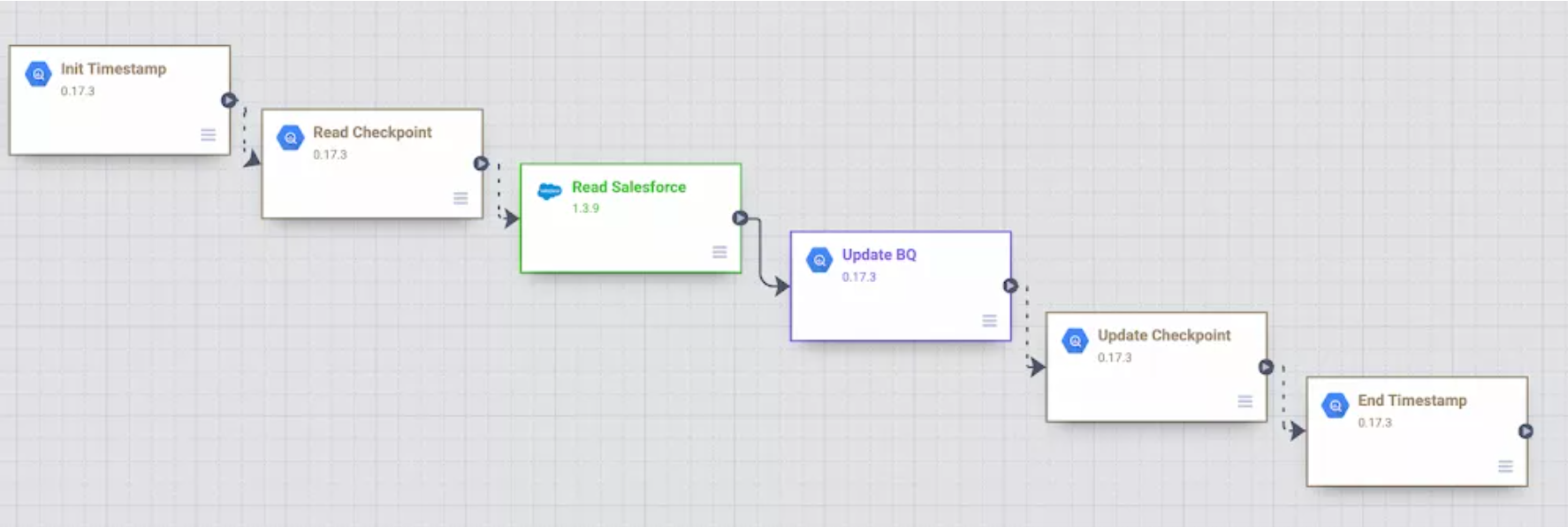
此示例管道的主要步骤如下:
- 对于这个自定义管道,我们决定在 BigQuery 中存储开始/结束时间并演示不同的 BigQuery 插件。管道启动时,时间戳存储在 BigQuery 中的用户检查点表中。此信息用于指导后续运行和增量逻辑;
- 通过使用 BigQuery Argument Setter 插件,管道从 BigQuery 检查点表中读取,获取要读取的最小时间戳;
- 在 Batch Multi Source 插件中,使用最小时间戳作为参数从 Salesforce 读取 lead、contact 和account 对象;
- 使用 BigQuery 多表接收器插件更新 BigQuery 表中的 lead、contract 和 account ;
- 检查点表更新为执行结束时间,然后更新 current_time 列;
我们可以通过 GitHub 下载自定义文件,并通过 Cloud Data Fusion 进行导入。完成导入之后,我们可以调整插件属性来观察自己的 Salesforce 环境。此外,我们还需要创建一个名为from_salesforce_cdf_staging 的 BigQuery 数据集,并在数据集 from_salesforce_cdf_staging 上创建一个 sf_checkpoint BigQuery表 ,如下所示:
- create or replace table from_salesforce_cdf_staging.sf_checkpoint
- (
- jobid string,
- last_completion string,
- current_max string
- )
导入: https://cloud.google.com/data-fusion/docs/how-to/exporting-pipelines#import
在 sf_checkpoint 表中插入以下记录:
- insert into from_salesforce_cdf_staging.sf_checkpoint values ('salesforce','1900-01-01T23:01:01Z',NULL)
需要注意的是,初始 “ last_completion date = " 1900-01-01 t23: 01:01z ” 表示第一次管道执行将读取 LastModifedDate 列大于1900-01-01的所有 Salesforce 记录。这是针对初始负载的一个样本值。根据需要调整 ast_completion 列,以反映初始运行的环境和要求。在多次执行这个示例管道之后,观察 sf_checkpoint.Last_completion 列如何随着执行完成变化的。
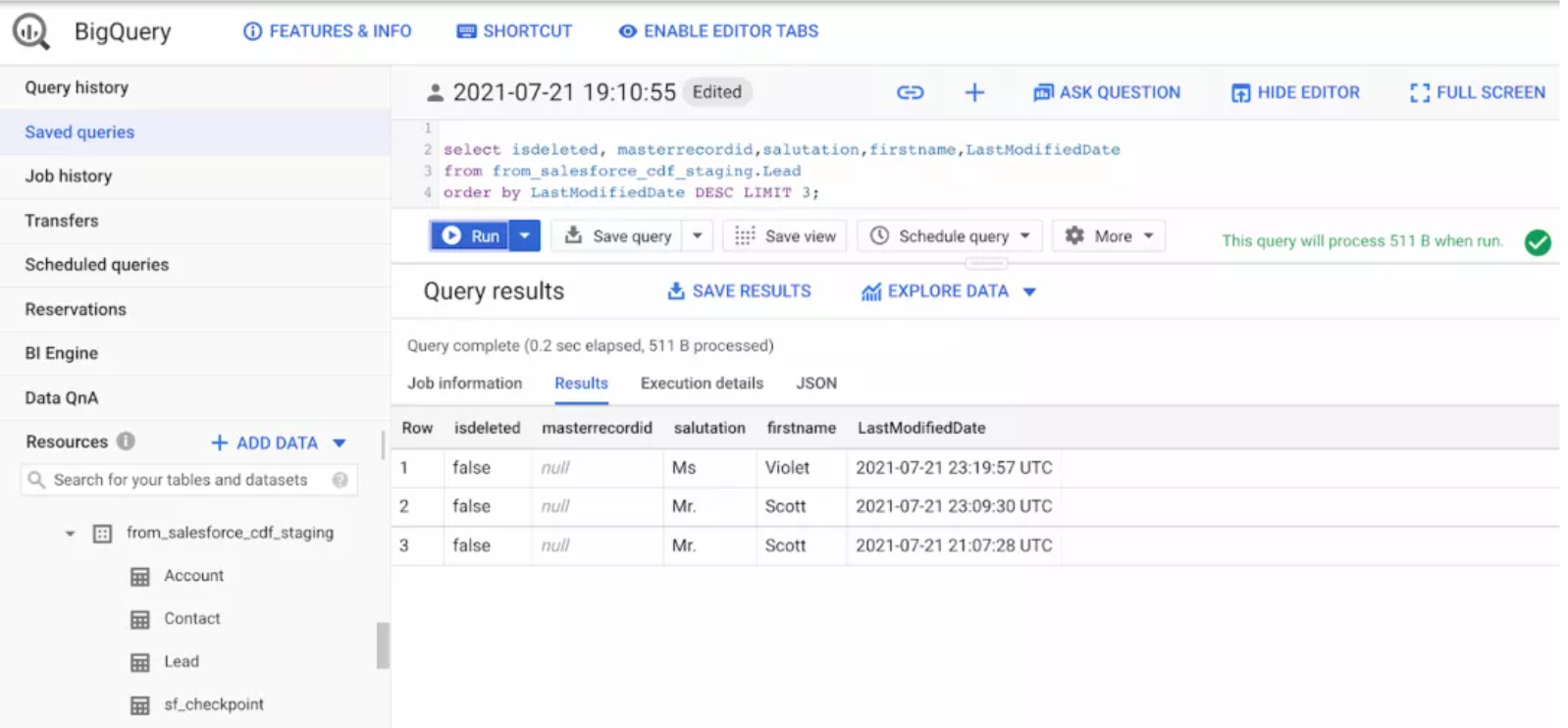
我们还可以验证更改是否以增量方式加载到 BigQuery 表中,如下所示:
流媒体流水线
将 Streaming Source 插件与 Data Fusion 结合使用时,可以使用 PushTopic 事件来跟踪 Salesforce sObjects 的变化。Data Fusion 流源插件可以让我们直接创建 Salesforce PushTopic,也可以使用之前使用的 Salesforce 工具已经定义好的 PushTopic。PushTopic 配置定义了触发通知的事件类型(插入、更新、删除)以及范围内的对象列。要了解有关 Salesforce PushTopics 的更多信息,可访问:https://developer.salesforce.com/docs/atlas.en-us.api_streaming.meta/api_streaming/code_sample_java_create_pushtopic.htm
流式传输数据时,无需在 BigQuery 中创建检查点表,因为数据几乎是实时复制的,一旦发生变化,就会自动仅捕获更改。如下面的示例所示,Data Fusion 管道可以变得非常简单。
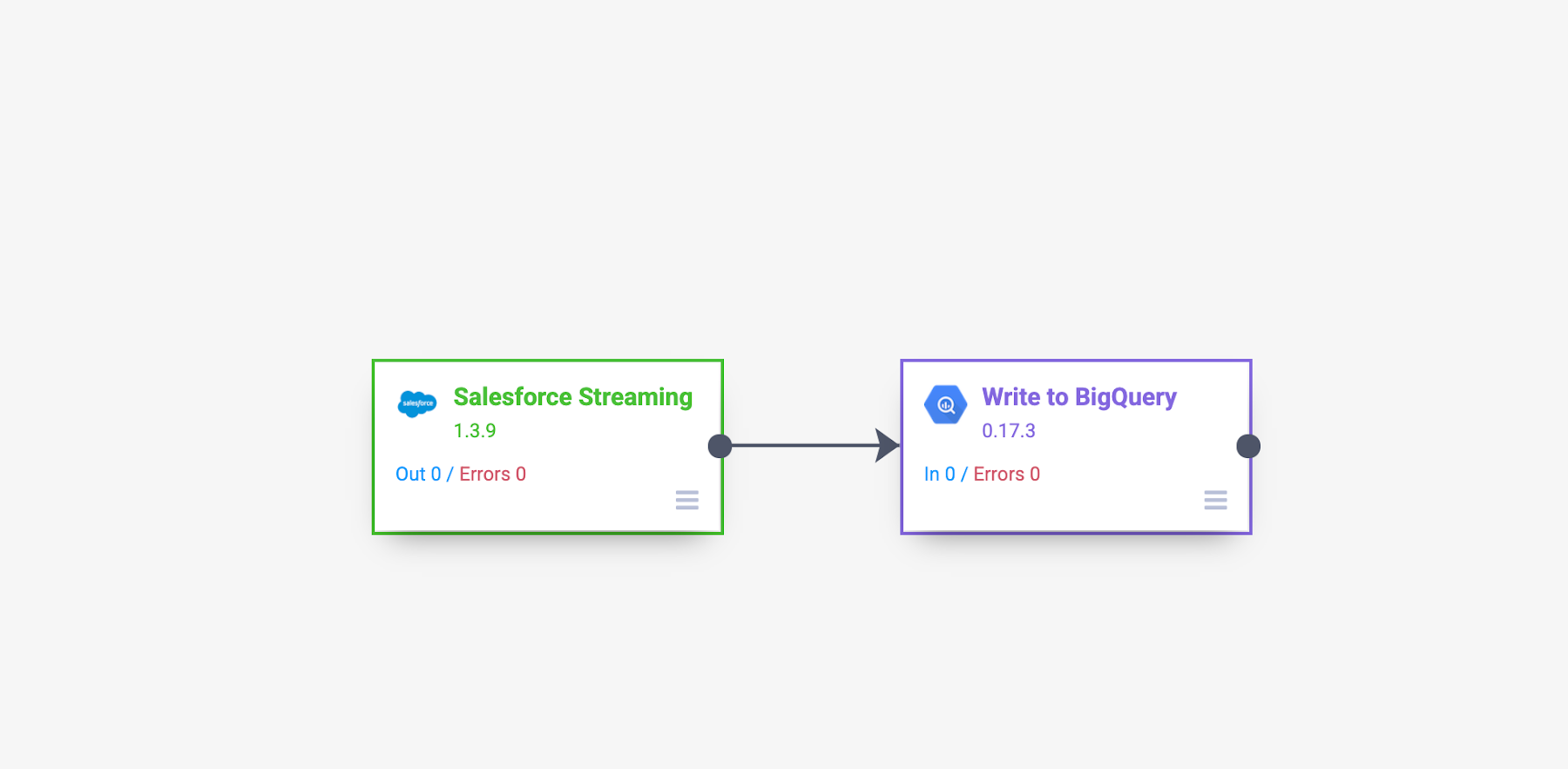
这个示例管道的主要步骤如下:
添加 Salesforce 流源并提供其配置详细信息。对于该实例,仅从 CDFLeadUpdates PushTopic 捕获插入和更新。作为参考,下面是用来在 Salesforce 中预创建 CDFLeadUpdates PushTopic 的代码。您也可以根据需要使用 Data Fusion 插件来预创建 PushTopic。
- PushTopic pushTopic = new PushTopic();
- pushTopic.Name = 'CDFLeadUpdates';
- pushTopic.Query = 'SELECT Id, IsDeleted, MasterRecordId, LastName, FirstName, Salutation, Name, Title, Company, Street, City, State, PostalCode, Country, Phone, MobilePhone, Fax, Email, Website, IsUnreadByOwner, CreatedDate, CreatedById, LastModifiedDate, LastModifiedById, SystemModstamp, LastActivityDate, LastViewedDate, LastReferencedDate, Status FROM Lead';
- pushTopic.ApiVersion = 52.0;
- pushTopic.NotifyForOperationCreate = true;
- pushTopic.NotifyForOperationUpdate = true;
- pushTopic.NotifyForOperationUndelete = false;
- pushTopic.NotifyForOperationDelete = false;
- pushTopic.NotifyForFields = 'All';
- insert pushTopic;
注意:要运行这个代码块,需要使用适当的权限登录 Salesforce,打开开发人员控制台并单击Debug | Open Execute Anonymous Window。然后我们向管道中添加一个 BigQuery 接收器,以便于接收流事件。我们会发现,一旦管道执行并生成第一个更改记录,BigQuery 表就会自动创建。
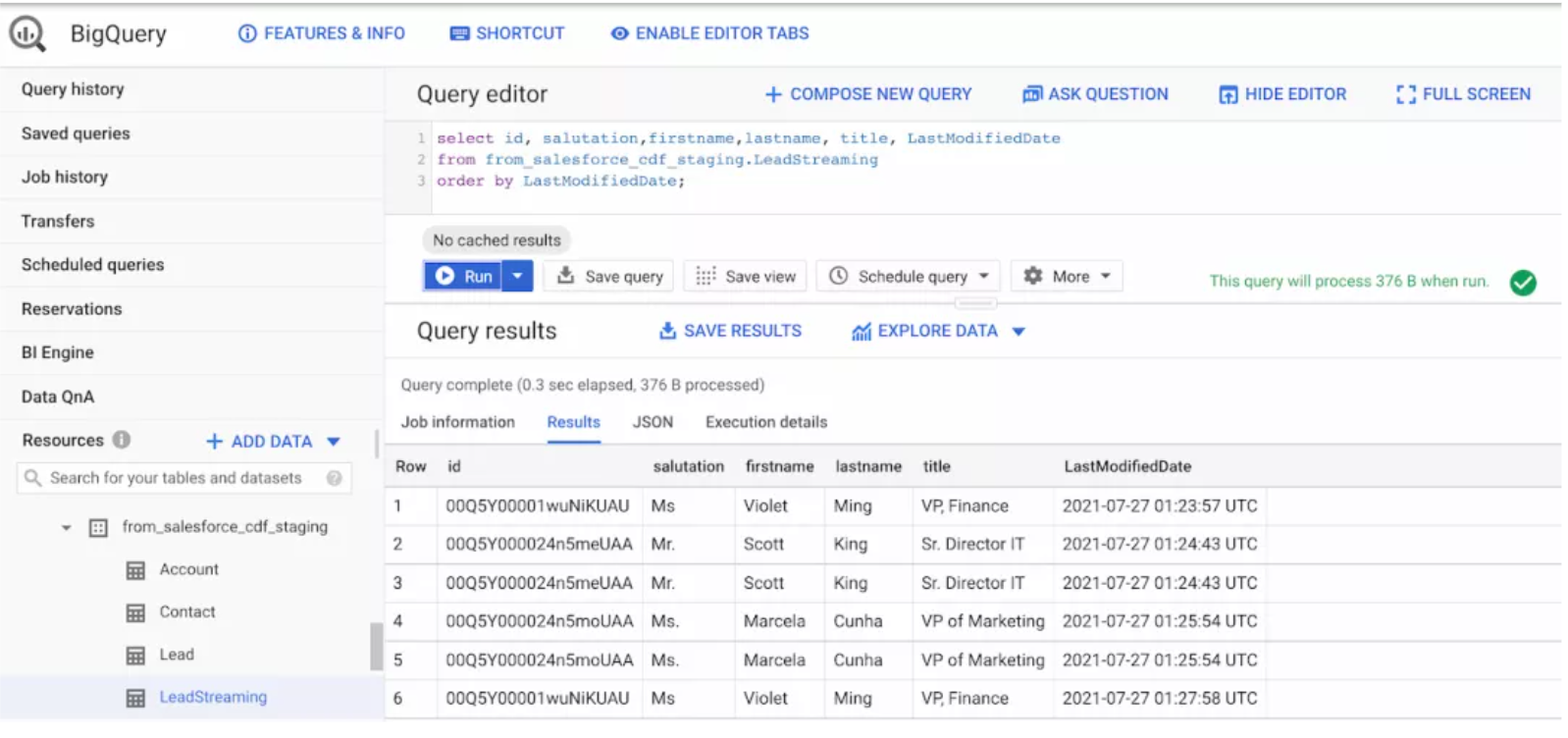
在启动管道之后,对 Salesforce 中的 Lead 对象做一些修改,观察流向 BigQuery 的变化,如下图所示:
同样,我们仍然可以从 GitHub 上下载该实例的自定文件并通过 Cloud Data Fusion 进行导入,完成导入之后,仍然可以调整插件属性来反映 Salesforce 的环境。(导入过程同上文一致)
另外,如果 Salesforce 实施时允许“hard deletes”,那我们我们可以对其进行捕获。以下思路可供参考:
- 用于跟踪删除的审计表。数据触发器可用于填充自定义审计表,我们可以使用 Cloud Data Fusion 从审计表中加载删除记录,并在 BigQuery 中比较或更新最终目标表;
- 额外的数据融合作业,从源读取主键,并与 BigQuery 中的数据进行比较合并;
- 捕获 Salesforce 变更数据;




