
揭秘!扒一扒 Document AI 是如何拯救 HR 们的头发的!
塞满存储桶的求职信息,五花八门的简历模板......每到求职季,每位 HR 都将面临筛选简历的“掉发”挑战。为从形形色色的简历当中准确提取候选人的关键信息,HR 们需在较长时间内保持极度的专注,不仅费时,还极易出现错看漏看的情况。
为了避免这种错误的发生,Google Cloud Document AI 利用自定义文档提取器 (CDE) 进行训练,帮助 HR 实现自动化的文档信息提取,让关键信息主动【现身】。
实际操作
创建自定义文档提取器处理器
按照标准产品文档链接中的步骤完成以下步骤:
1. 创建处理器
2. 为数据集创建 Cloud Storage 存储桶
3. 将文档导入数据集
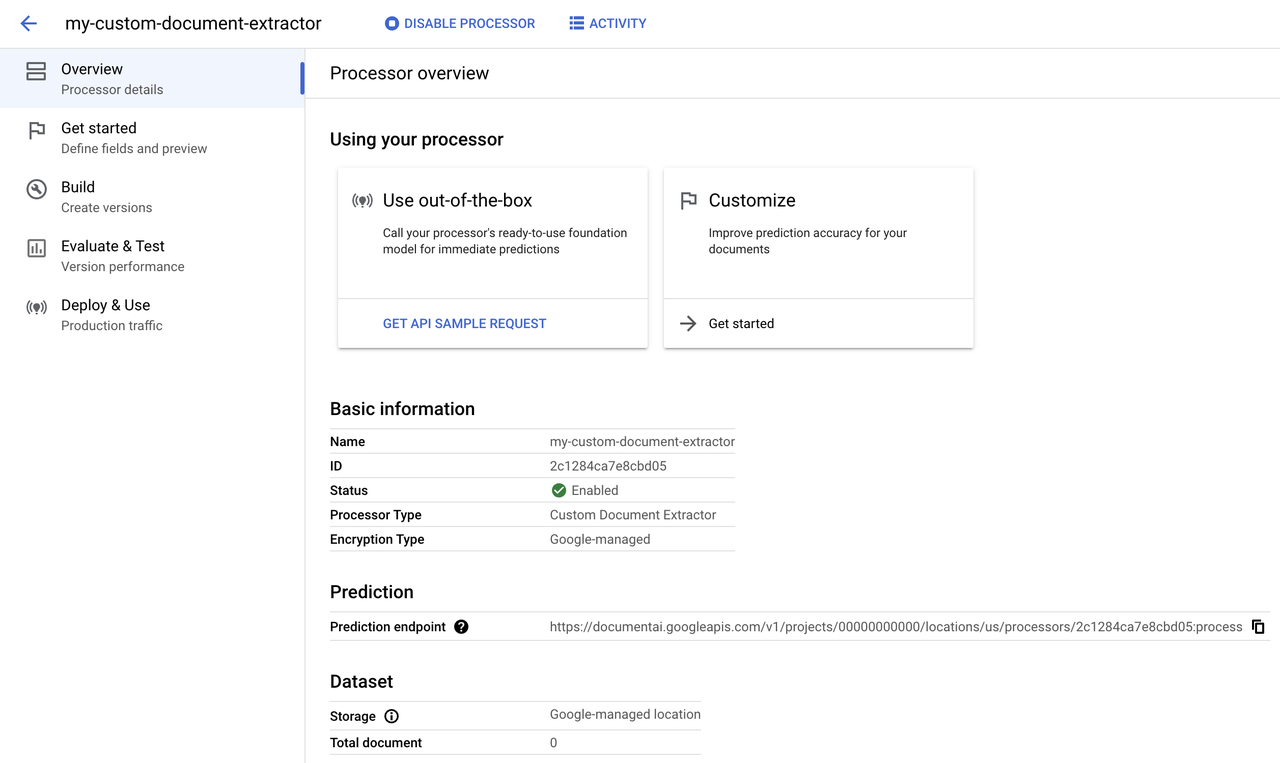
导入数据集信息
为了创建此简历示例的数据集,从多个网站下载了250多种不同格式的现代简历文档样本,用于在训练中创建品种,并将文档上传到云存储桶中,然后导入到 Document AI 数据集中。
该数据集中使用的格式:PDF、JPEG、PNG 和 WEBP。
训练样本数据集
在这步中您将看到如何训练模型来提取下面突出显示的标签。
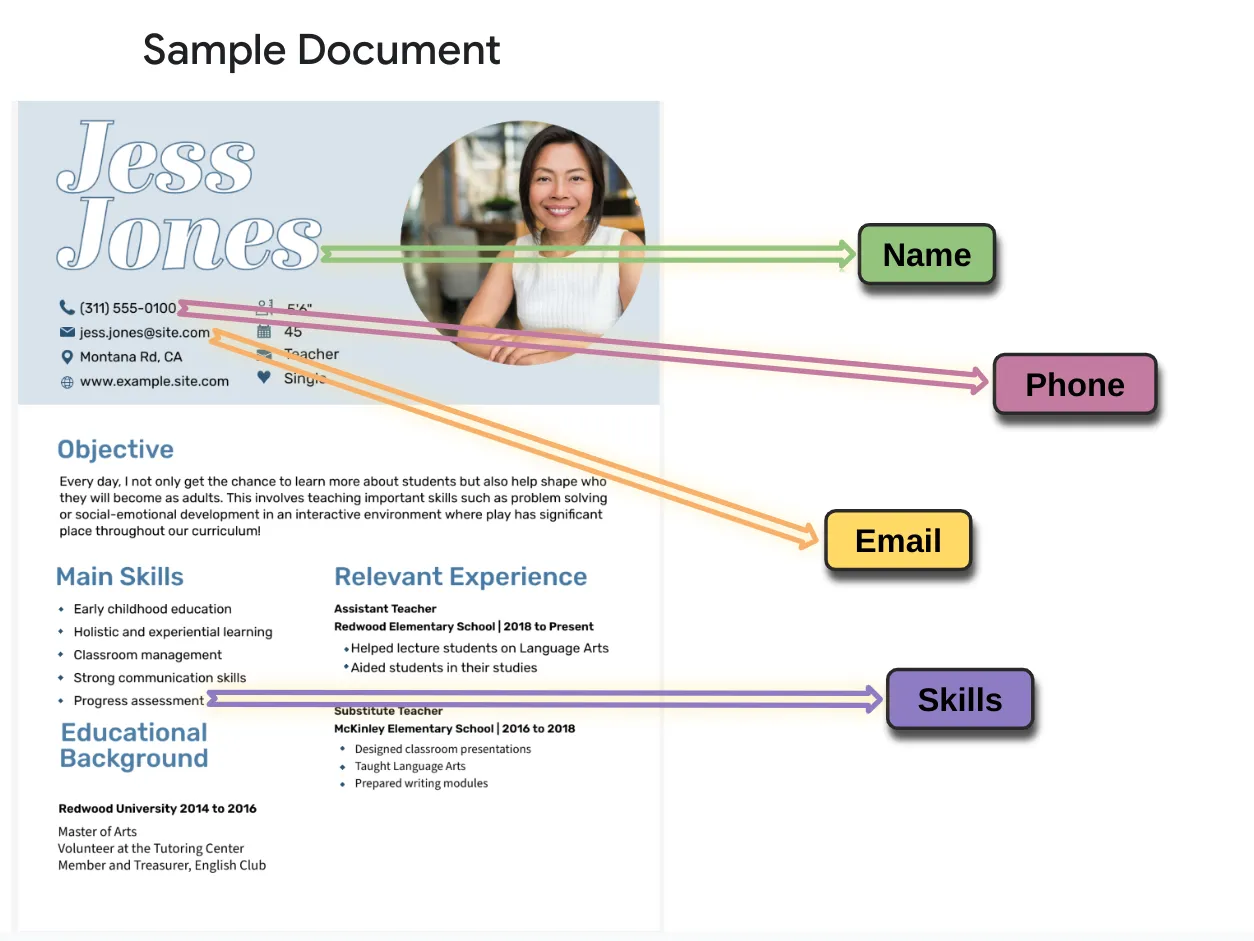
- 创建标签
完成导入后,您可以创建将在文档中搜索的标签。您可以在开始为文档添加标签之前随时执行此步骤。单击 [TRAIN] 选项卡左侧窗格中的 [EDIT SCHEMA] 按钮。
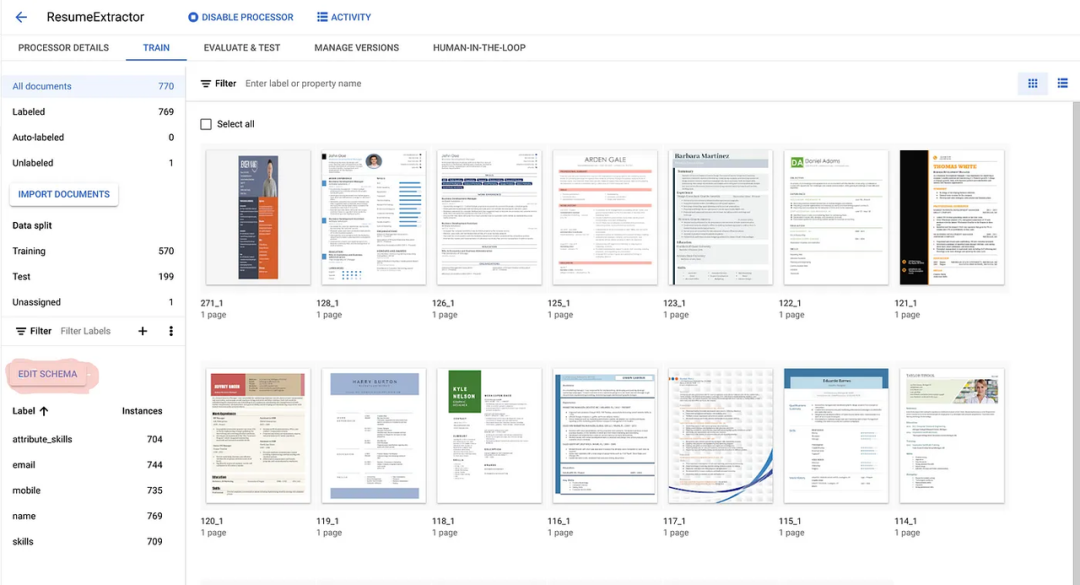
使用所需的数据类型和出现次数创建所有所需的标签,然后单击 [SAVE]。
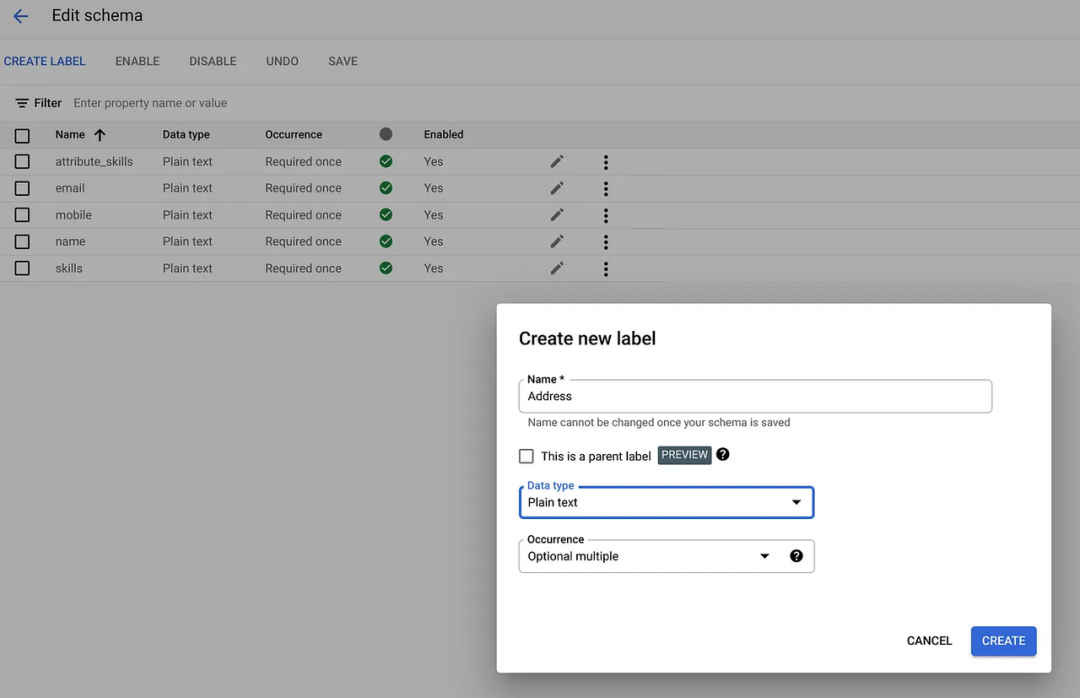
- 为新导入的文档添加标签
在此用例中,您将了解如何手动标记文档。现代简历被视为该数据集的文档。
要开始标记,请单击 [Unlabeled/Auto-labeled] 下的导入文档。
对于 [Unlabeled] 池下的文档(将在数据集中首次导入文档后填充),您必须在每个文档上的所需数据上手动创建边界框,并将标签映射到它们。
对于 [Auto-Labeled] 池下的文档,您将在文档上绘制预测标签的边界框,该边界框是在您通过 [Auto-labeling] 选项导入数据时创建的。您必须确认/更正自动标记的数据并保存。此过程可以节省时间并加快标记速度。
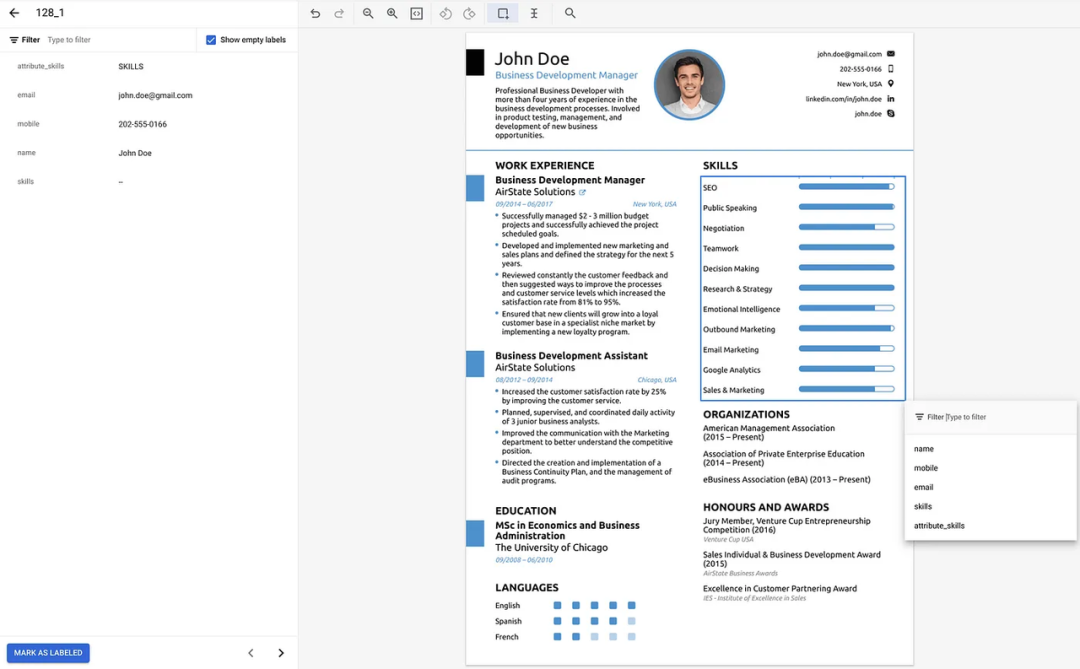
在下面的示例中,我们在技能数据周围创建了一个边界框,并将名为技能的标签映射到它,然后在文档上发布标签所有数据,单击“标记为标签”按钮进行保存,发布此文档将从 Unlabeled/Auto-labeled 池到 Labeled 池。
- 将文档分配给训练和测试集
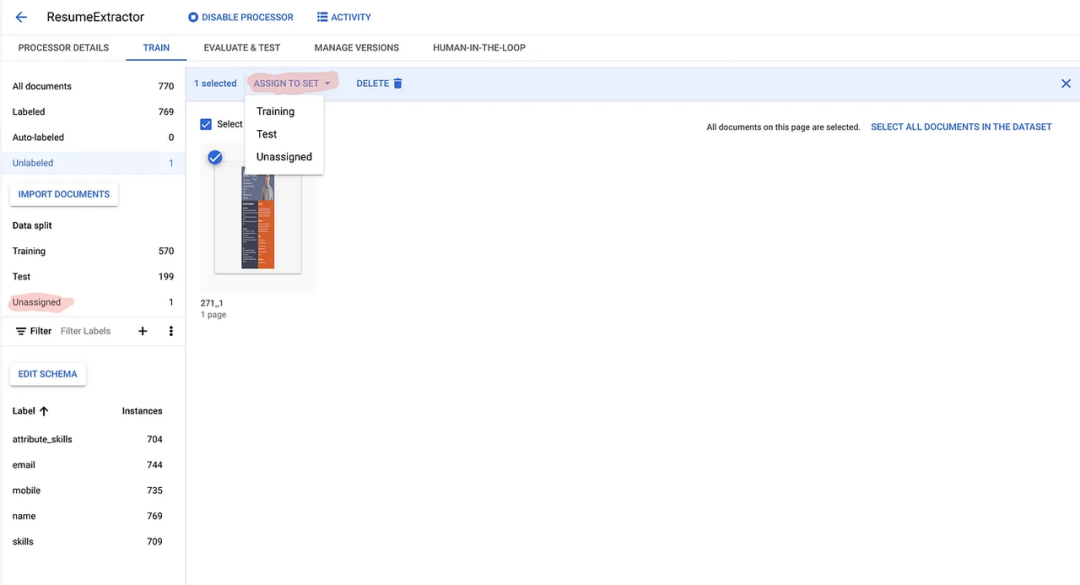
完成标记过程后,您必须在训练集和测试集之间分发文档。考虑将至少50个文档(每个文档中包含所有标签)分配给训练集和测试集。
训练处理器
数据分发完成并满足最低标准后,单击 [TRAIN NEW VERSION] 按钮在 [TRAIN] 选项卡下开始训练。
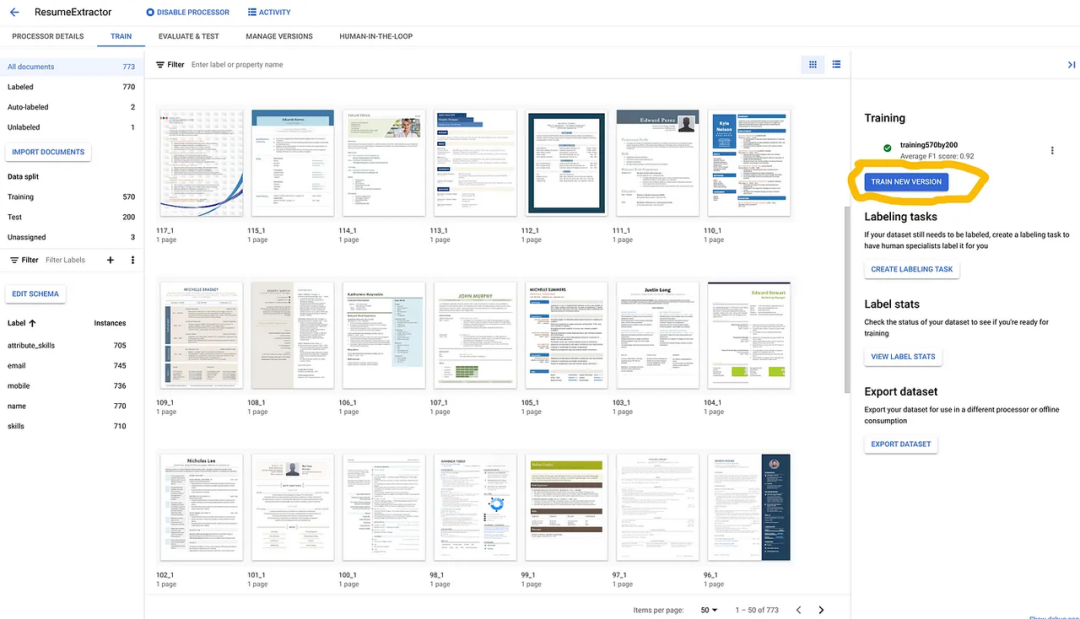
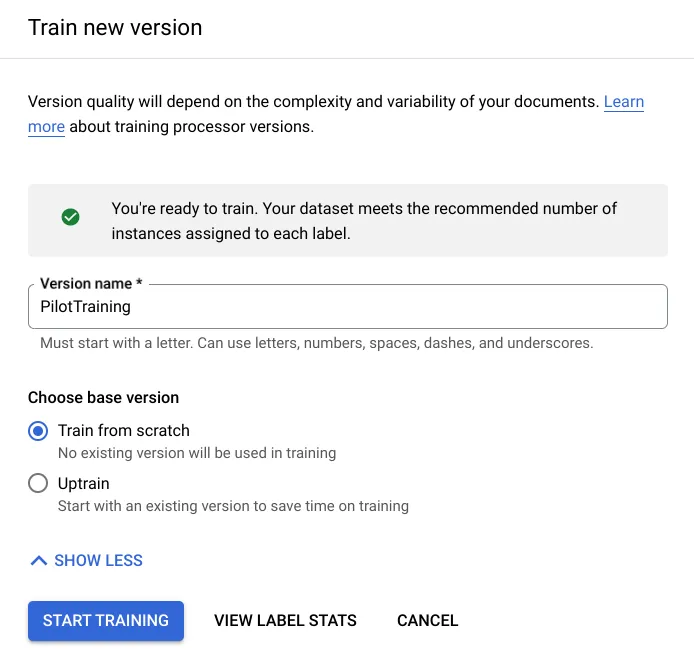
在开始训练之前,您可以通过单击上一个屏幕截图中的 [VIEW LABEL STATS] 按钮来查看训练集和测试集之间的标签分布。您可以在下面看到您在培训指南中获得了绿色勾号,这是良好培训所必需的。
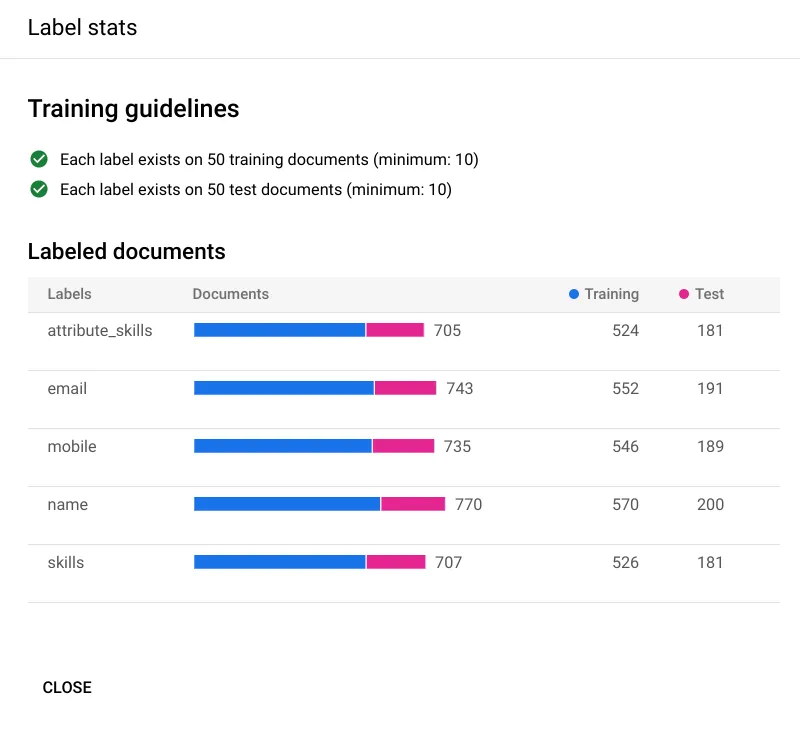
满足训练要求后,即可点击 [START TRAINING] 按钮。训练模型需要所需的时间,因此开始训练后请耐心等待。训练时间取决于数据集中文档的复杂性和数量。
部署处理器
需要部署该版本来测试处理器。您可以在 [MANAGE VERSIONS] 选项卡下选择要部署的版本,如下所示:
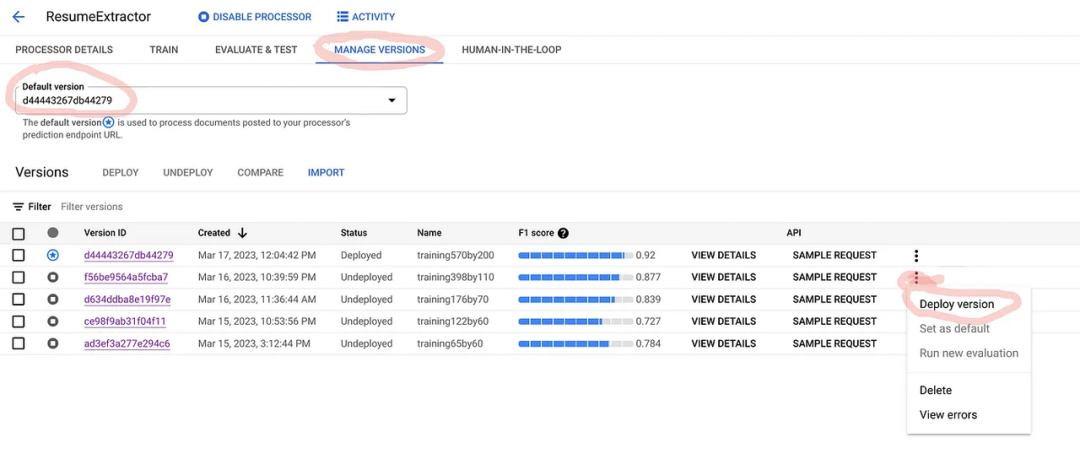
部署将需要几分钟时间。之后,您可以测试示例文档。
评估处理器
部署完成后,您可以在 [Evaluate & Test] 选项卡下选择版本来评估模型.
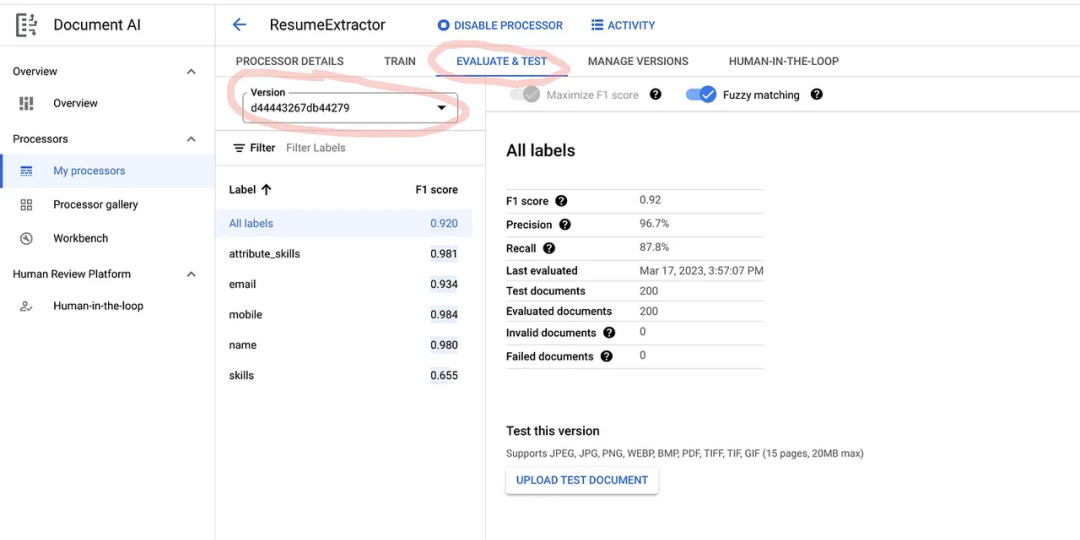
可以看到,对于一个好的模型来说,F1 分数、精确度和召回率应该较高。
测试效果
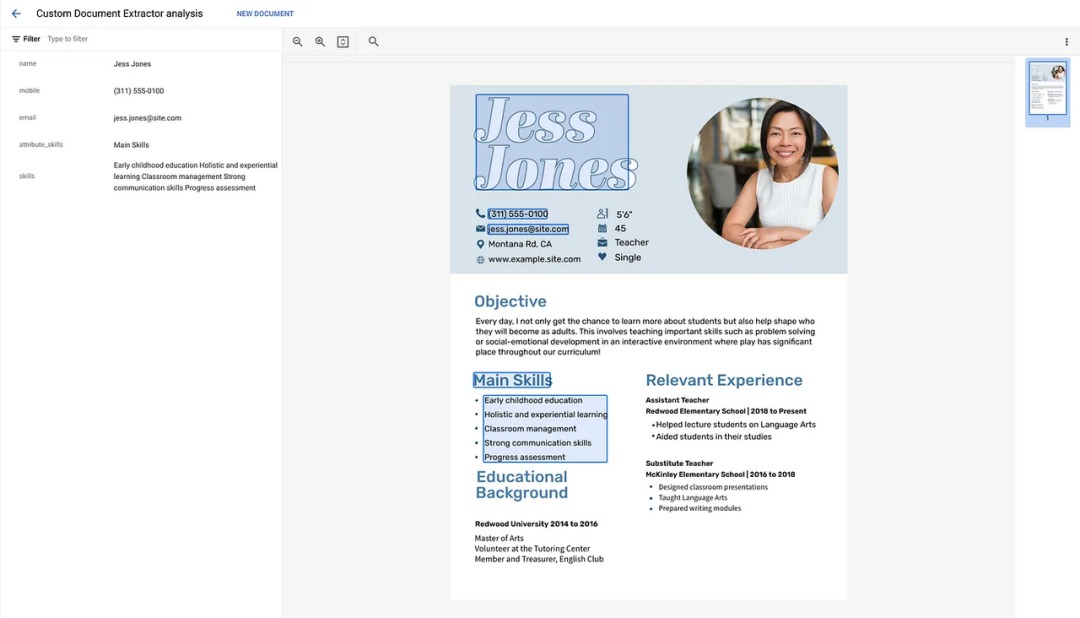
在 [EVALUATE & TEST] 选项卡中,您可以上传数据集的示例文档并检查训练标签的预测。在我们的用例中,上传了两份简历样本进行评估。
通过 API 调用训练好的模型
详细代码可以参考链接https://cloud.google.com/document-ai/docs/send-request,该代码提供 REST、Java、C#、Python、Node js 等多种语言版本。
您可以在此文档 API 之上创建自己的 API/云函数来使用经过训练的模型。然后,您可以将输出存储在任何数据库(例如 BigQuery)中,并使该数据可用于分析。
Document AI 的自定义文档提取处理器是一款功能强大的工具,可以帮助企业自动执行手动数据提取任务、提高数据准确性、增强客户体验并提高合规性。目前,Document AI 目前支持PDF、WEBP、BMP等多种格式的训练,同时也支持多种语言的信息提取。

如您对该功能感兴趣,可扫描文章下方助手二维码联系我们。




