
如何在 GKE 配置多维 Pod 自动扩缩
在Google Kubernetes Engine(GKE)中,应用程序所有者可以使用单个Kubernetes资源为多维数据集定义多种自动缩放行为:多维Pod自动缩放器(MPA)。
横向和纵向扩缩 Pod 的挑战
Kubernetes 作为被广泛采用的平台的成功在于其对各种工作负载及其许多需求的支持。随着时间的推移,持续改进的领域之一是工作负载自动缩放。可以追溯到 Kubernetes 的早期,Horizontal Pod Autoscaler(HPA)是 Pods自动缩放的主要机制。就其名称的本质而言,它使用户能够在超过给定指标的用户定义阈值时添加 Pod 副本。最初,通常是 CPU 或内存的使用情况,不过现在支持自定义指标和外部指标。
再往后一点,Vertical Pod Autoscaler(VPA)为工作负载自动缩放添加了新的维度。顾名思义,VPA 能够根据使用模式对 Pods 应请求的最佳 CPU 或内存量提出建议。然后,用户可以查看这些建议并就是否应该应用这些建议进行呼叫,或者委托 VPA 代表他们自动应用这些更改。
自然地,Kubernetes 用户一直试图从这两种扩展形式中受益。
尽管这些自动缩放器相互独立运行良好,但同时运行这两种结果可能会产生意外的结果。
下图就是一个例子:

- HPA调整Pod的副本数以将目标 CPU 使用率保持在50%
- 将VPA配置为自动应用建议时,它可能会陷入不断减少的CPU请求的循环–这是HPA维持其相对较低的 CPU 使用率目标的直接结果!这里的挑战之一是,当配置为自主运行时,VPA 将更改同时应用于 CPU 和内存。因此,只要 VPA 自动应用更改,争用就会很难避免。
此后,用户已经通过以下两种方式之一接受了折衷方案:
- 使用 HPA 在 CPU 或内存上扩展,仅将 VPA 用于建议,构建自己的自动化机制以查看并实际应用建议
- 使用 VPA 自动将更改应用到 CPU 和内存,同时使用基于自定义或外部指标的HPA
- 尽管这些变通办法适用于少数用例,但仍然可以通过在 CPU 和内存的整个维度上自动扩展而受益。
例如,Web 应用程序可能需要在绑定 CPU 时在 CPU 上进行横向自动缩放,但也可能希望在内存上进行纵向自动缩放以确保可靠性,如果内存配置错误会导致容器发生 OOM 终止事件。
多维Pod自动缩放器
MPA 中提供的第一个功能允许用户根据 CPU 利用率横向扩展 Pod,并根据内存纵向扩展 Pod,这在 GKE 群集 1.19.4-gke.1700 或更高版本中可用。
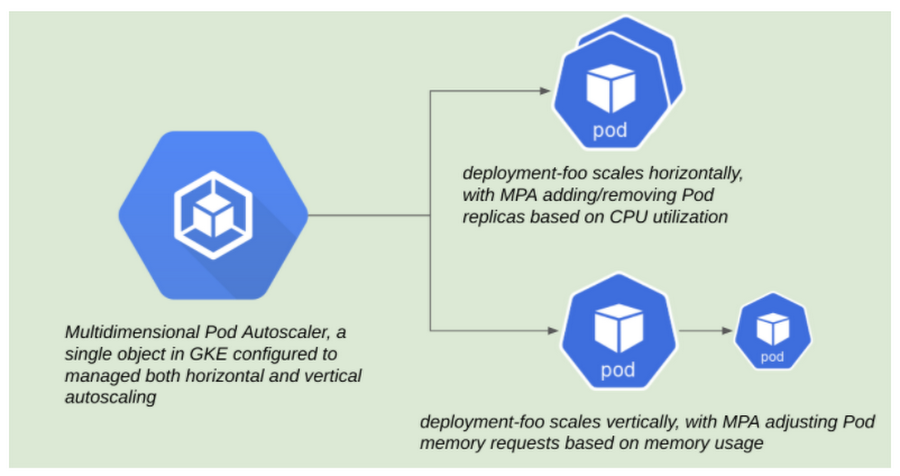
在 MPA 模式中,有两个关键结构使用户能够配置他们期望的行为:目标和约束。请参阅以下 MPA 资源的示单,该列表已缩短以实现可读性:
# mpa-config.yaml
...
goals:
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60
constraints:
global:
minReplicas: 1
maxReplicas: 5
containerControlledResources: [ memory ]
policy:
updateMode: Auto
...
目标允许用户定义指标目标。第一个支持指标是目标 CPU 利用率,类似于用户如何定义 HPA 资源中的目标 CPU 利用率。MPA 将尝试通过在给定 Pod 的其他副本中分配负载来确保实现这些目标。另一方面,限制要严格一些。这些目标优先于目标,可以应用于全球目标(考虑给定 Pod 的最低和最大副本)或特定资源。在纵向自动缩放的情况下,这是用户到达 a. 指定内存由 MPA 和 b 控制)如果给定 Pod 需要,则定义其内存请求的上下边界。
下面我们测试一下!
我们将使用 Cloud Shell 作为工作站,并使用支持 MPA 的版本创建 GKE 集群:
gcloud beta container clusters create "mpa-sandbox" \
--cluster-version "1.19.6-gke.600" \
--release-channel "rapid" \
--enable-vertical-pod-autoscaling
我们将使用 HPA 上 Kubernetes 文档中的标准 php-apache 示例 Pod。这些清单将创建三个 Kubernetes 对象-部署,服务和多维 Pod 自动缩放器。
kubectl apply -f https://raw.githubusercontent.com/agmsbush/mpa-gke/main/php-apache-mpa.yaml
部署由 php-apache Pod 组成,通过服务类型暴露:负载平衡器,并由多维 Pod 自动缩放器 (MPA) 管理。
部署中的 Pod 模板配置为在 CPU 中请求 100 毫核,在内存中请求 50 兆字节。MPA 的配置旨在实现 60% 的 CPU 利用率,并根据使用情况调整 Pod 内存请求。
部署资源后,获取 php-apache 服务的外部 IP 地址。
kubectl get svc
然后,我们将使用 hey 实用程序将人工流量发送到我们的 php-apache Pods,从而触发 MPA 的行动,通过服务的外部 IP 地址访问 Pods。
hey -z 1000s -c 1000 http://<your-service-external-ip>
然后,MPA 将水平扩展部署,添加 Pod 副本以处理传入的流量。
kubectl get pods -w
我们还可以观察每个 Pod 副本使用的 CPU 和内存量:
kubectl top pods
在上一个命令的输出中,Pods 应远远超过我们在部署中指定的内存请求。在挖掘 MPA 对象时,我们可以看到 MPA 也注意到这一点,建议增加内存请求。
kubectl describe mpa
…
Recommended Pod Resources:
Container Recommendations:
Container Name: php-apache
Lower Bound:
Memory: 78643200
Target:
Memory: 179306496
Uncapped Target:
Memory: 179306496
Upper Bound:
Memory: 81285611520
...
最终,我们应该看到MPA提出了这些建议并纵向扩展了 Pod。
我们将通过在 Pod 中观察一个表示MPA采取了措施的注释以及经过调整以反映MPA 行为的新内存请求,来了解到这一点是完整的。
kubectl describe pod $POD_NAME
...
Annotations: vpaObservedContainers: php-apache
vpaUpdates: Pod resources updated by php-apache-mpa: container 0: memory request...
...
Requests:
cpu:100m
memory: 171966464
...
结论
多维Pod自动缩放器解决了许多GKE用户面临的挑战,它公开了一种通过单个资源控制横向和纵向自动缩放的新方法。在GKE快速通道中当前可用的GKE 1.19.6-gke.600 +版本中进行试用。
试用:
https://cloud.google.com/kubernetes-engine/docs/how-to/multidimensional-pod-autoscaling
编译自:Scaling workloads across multiple dimensions in GKE




