
多角度探讨灵活可扩缩的云上游戏解决方案
在上周的 Cloud 干货中我们从谷歌的基础架构入手,分析了其在游戏场景中的几大独特优势:优质层级的网络服务、全球 VPC、负载均衡等(点此复习)
那我们今天的文章继续来聊聊如何借助 Google Cloud来打造灵活可扩缩的游戏解决方案,简单来说主要分为三个层面:游戏接入层、服务器、数据库的扩展方案。
下面我们逐一展开.....
游戏接入层的扩展
正式开始之前我们先来看一个短视频:
这里主要有四个数字需要关注
一、随着玩家的不断加入,请求新开服务器的数量
二、实际开起来的服务器的数量
三、正在运行的服务器的数量
四、同时在线的玩家数量
我们会发现,一和二是完全匹配的,且游戏服务器的数量跟随玩家数量呈正向变化。这就是我们经常会听到的 Google Cloud 的自动、按需扩展。
且注意,Google Cloud 的自动扩展是不需要预热的。
那么,什么是预热呢?
在实际情况下,游戏厂商不只会有一台主机,会同时有很多游戏服务器,在这些服务器按之前还会有一个类似于负载均衡 Load Balancer 的服务,负责接受玩家请求,并将其分配给某台游戏服务器。这里的负载均衡本身可能是一个虚拟机(也可能是一台物理设备),当数以万计的玩家涌入时,同样需要对其扩展,否则会成为服务的瓶颈。
负载均衡的扩展即预热,需要时间和人工进行干预。
那么 Google Cloud 如何做到无需预热、按需扩展?
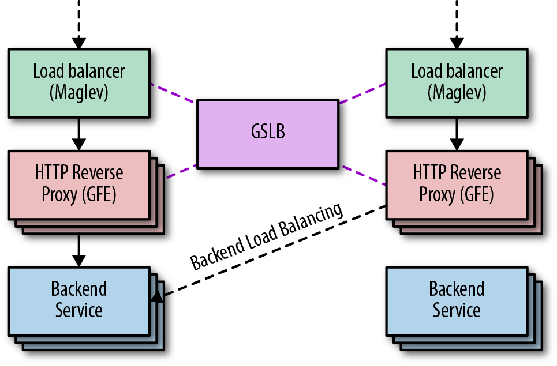
事实上,Google 的 Load Balancer 并不依赖某一台物理设备,甚至不依赖于某一机器集群,也不是单一的一个服务,而是由一组服务组成的一个遍布全球的分布式系统。从2008年开始,Google Cloud Load Balancer的很多关键服务,就一直在支持Google Search / Map / Adwords等多个业务的全球扩展。
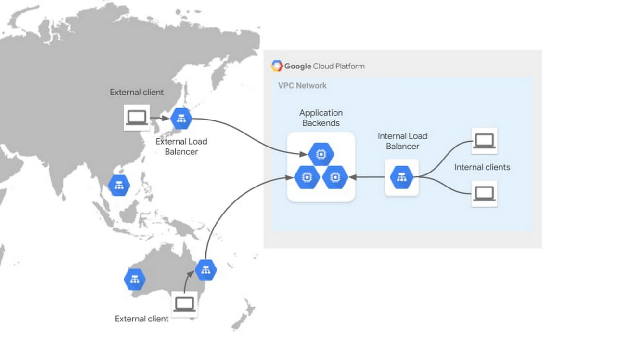
另外,在之前的文章中,我们说到的“就近接入”,Google 的 Load Balance 并不在云的 VPC 里面,而是遍布在全球144个 POP 节点上,而且,在将用户请求负载均衡到位于 Google Cloud 的应用之前,会在靠近用户的边缘站点处终止用户的 TCP 连接。它还为 SSL 连接提供证书。这样做的好处之一,就是可以利用Google 的骨干网络,加速用户访问的速度。
游戏服务器的扩展
游戏服务器到底应该放在虚拟机还是容器上?
这个问题其实并没有标准答案,完全取决于业务情况以及团队的技术能力。
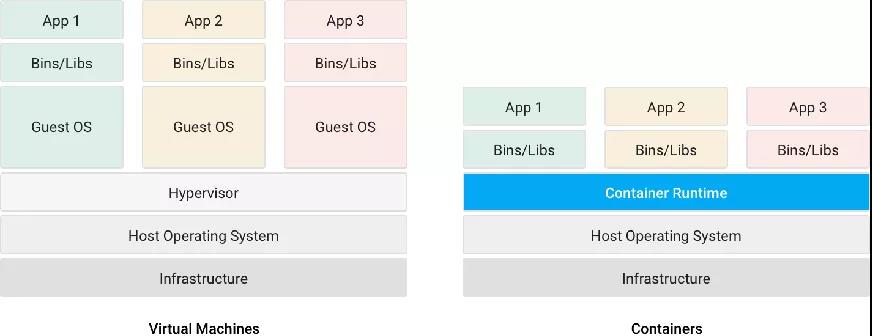
但是我们需要注意的是,每台虚拟机都有独立的操作系统,彼此之间隔离性较好。同一个宿主机上,当一台虚拟机瘫痪之后不会影响其他虚拟机,持久性也会更好。如果之前您的游戏是运行在物理机上的,迁移至虚拟机时要比到容器上的学习成本更低一些。
当然,容器的好处在于同一台主机上,共享同一个操作系统内核,可以更快更轻启动。另外在同一台宿主机上,可以比虚拟机装更多的容器,充分利用机器的资源。同时,容器的打包部署速度比较快,也比较简单,可以给予用户持续集成和持续部署的能力。
但是就像微服务给我们带来好处的同时把这个复杂性甩给了网络一样。那么容器也给我们带来很多新的挑战。比如:

为了解决这些问题,Google 开源了容器编排管理工具 Kubernates (Google在其多个核心业务中,使用容器技术已超过十年,每周都会发布将近20亿个新容器)可以解决的问题包括:
-编排: 决定在哪儿运行容器
-健康检查: 确保容器运行在期望的状态
-扩展: 增加或者减少容器数量
-发现: 寻找某个容器的位置
-负载均衡: 在多个容器之间分发流量
-存储: 保存数据
-日志与监控: 追踪容器的事件、指标
-调试: 定位问题
-验证与授权: 控制谁可以对哪个资源做什么操作
针对游戏领域,在2019年 Google Cloud 联手 UBISOFT 打造了一款叫做Agones 的开源项目。
Agones 被设计用来托管和扩展游戏服务器, 它构建在 Kubernetes 之上,灵活性非常好,可根据多人游戏需求进行定制。
相较于直接在 Kubernetes 上直接搭载游戏服务器,Agones 的好处主要有以下几点。
首先 Agones 在 Kubernetes 之上,使用游戏开发者熟悉的语言和概念,又做了一层封装,例如:Game Fleet、Game Server等,会大大缩短了游戏开发者的学习时间,降低了入门门槛。
其次,也是非常重要的一点,Kubernetes 并不知道集群里某一个 POP 上正在有人打游戏。那么在 Scale in 的时候,可能会误删正在运行的游戏服务器,给玩家带来非常糟糕的游戏体验。
另外,Agones 还提供了更加丰富的SDK,如:Unreal 、Engine 、Unity、 C++、 Node.js、 Go Rust、REST 。
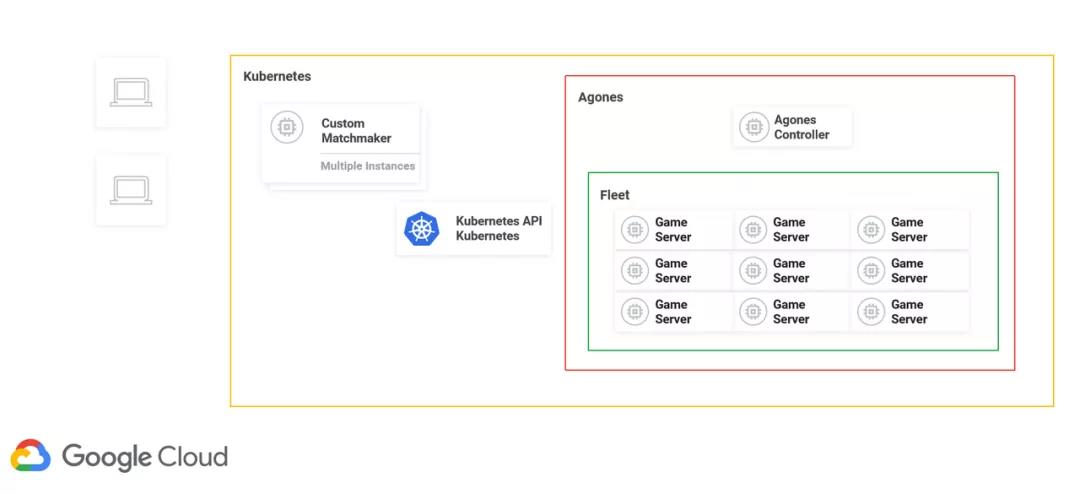
通过上方的架构图可以看到当更多的玩家加入请求对战时,他们的请求会被发到 Matchmaker,即匹配服务。
我们注意这个服务,并不是 Agones 提供的一个功能,你可以使用自己任意喜欢的匹配服务。匹配好了以后,通过 Kubernetes 来请求分配给玩家一台游戏服务器。
这时Agones会去调用 Agones Controller, Agones Controller 会从图片下方 Fleet 里面找出一台游戏服务器,然后把这台游戏服务器的端口的 IP 地址返回到游戏客户端,然后游戏客户端就可以连上来,进入愉快的游戏时间。
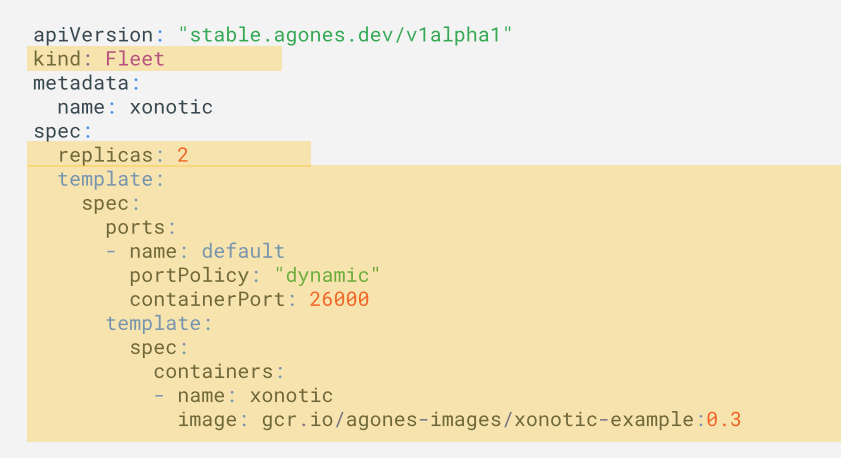
百闻不如一见,下面我们来看一段 demo,看一看如何在这个通过 Agones 来创建一台及一组服务器。
在这个 Demo 中我们看到的是手工扩展的方式,那么有没有自动扩展的方式呢?
有,且有两种。
其一是 Buffer Size ,即在任何时候,需要有多少台机器被分配出去,通过 bufferSize 可以直接进行指定,如在下图中指定了永远有两台 ready 状态的服务器可以用于分配,当然通过 minReplicas 和 maxReplicas 可以指定用于分配的服务器数量的上下限。
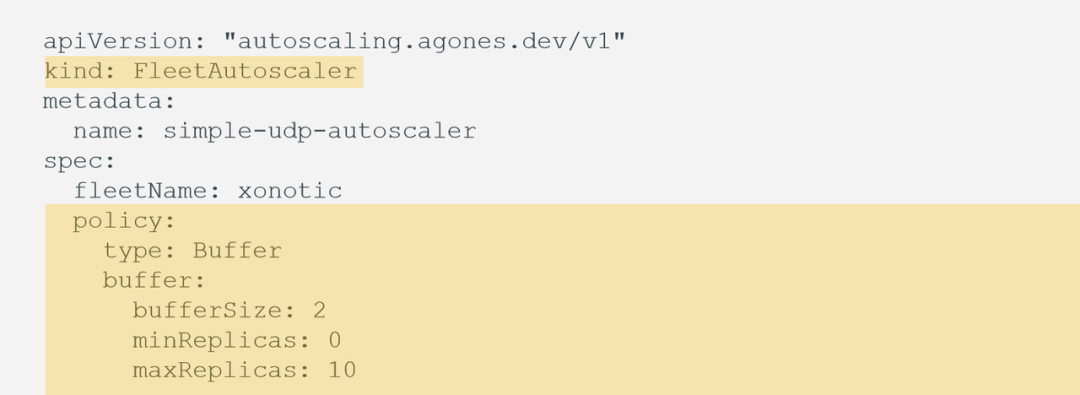
另外一种方式是 Webhook ,通过Webhook 我们可以自定义一个 Webhook Service ,进行指标自定义及触发扩展或收缩的动作。
当然,为了让游戏开发者更加专注于游戏开发而不是底层资源管理,2019年 Google Cloud 还推出了一个托管服务:Game Sever,使用它的好处在于:
-选择 可管理运行在GKE上的游戏服务器集群,未来还将支持混合云 / 多云的管理。
-灵活性 可以跟包括Open Match在内的多种匹配服务结合使用。
-可视化 可视化的管理界面和监控界面。
-简化 发布之前可以先Preview。支持在全球范围内统一发布,也可以在不同区域定制化部署。
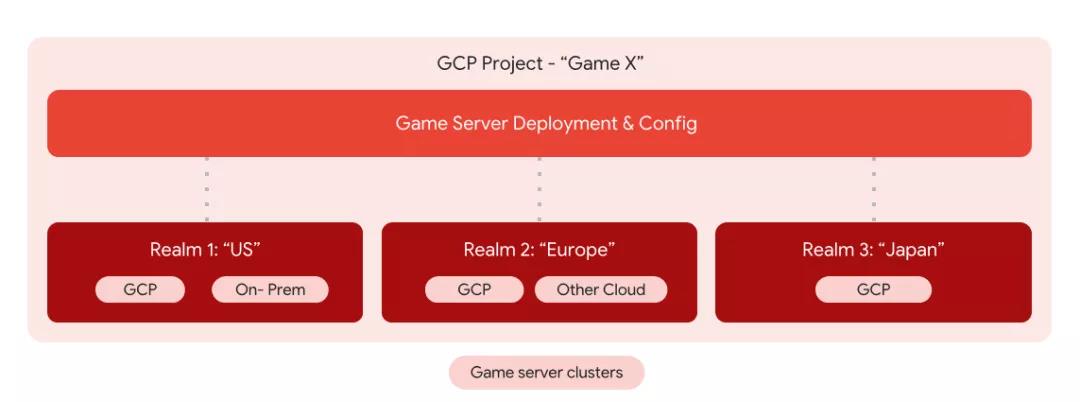
其中简化管理非常重要,Agones 更适合于一个 Region ,即一个区域管理一个集群,如果您的游戏是跨多个区域的,每个区域有多个集群,甚至在不同的集群上跑着不同的游戏。这个时候 Game Sever 就会派上用场了,首先这里我们要明确两个重要的概念:
发布, Game Sever 的一次发布即游戏的一个版本。
Clusters,即配置,这里可以全球同一个配置,也可以不同区域不同配置,如下图。
游戏数据库的扩展
数据库的扩展应该是三个部分中最难的,这是因为传统的数据库往往会成为限制游戏性能的瓶颈。
因为从第一天开始,它就被设计为一个单点,很容易出现单点故障。
那么解决方法之一就是对传统数据库进行分片,思路就是把数据分成很多份。然后每一份数据扔到不同的数据库服务器上,比如下图左边所示,根据玩家的id 进行分片,a 到m 开头的玩家,分配到数据库服务器一,剩下的分配到数据库二。同理,我们也可以根据玩家地理位置或者玩家使用的设备类型进行分片。
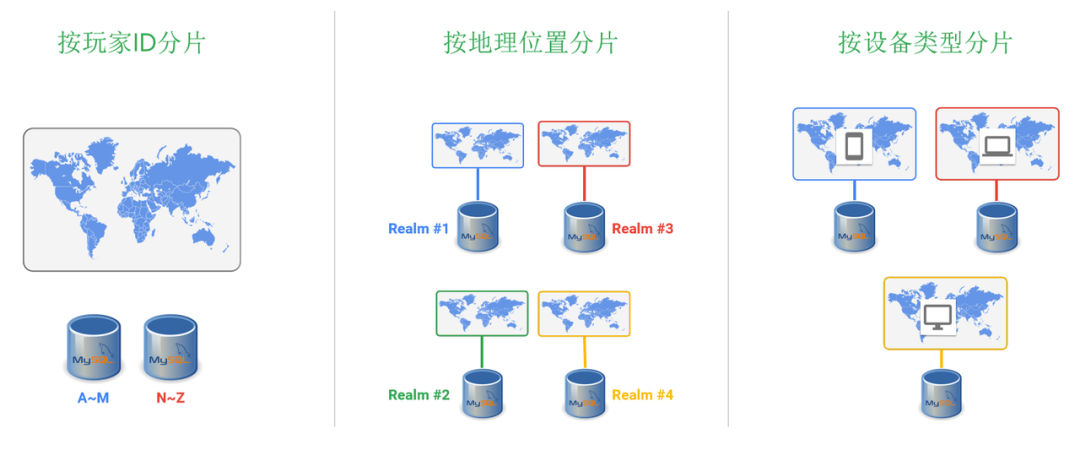
分片虽好,但是也带来了很多的问题。
比如说维护成本很高。举个例子,一台数据库可以支持最多一万个玩家的请求。那么如果有一百万的玩家,就需要一百台数据库服务器。
第二就是可升级性、维护性较差。我们知道游戏的玩家是来自于五湖四海,游戏的时间也会比较分散。很难找一个合适的时间对数据库 Shutdown 来进行升级维护或者打补丁。
另外就是服务可用性的保障。最重要的是数据分片以后,数据的管理就会变得异常复杂,容易出现问题。举个例子,我们需要统计某款游戏中哪一个角色被使用的最多。数据库服务器一统计出来是角色一,服务器二统计出来的是角色二。但是有一种可能,角色三,在每一台数据库服务器上统计出来的都不是 Number One,但是加在一起它就是最受欢迎的角色。这就是数据汇总的问题,但涉及到数据汇总背后又会牵扯到很多复杂的事情,如数据如何跨节点输出、如何保持数据一致性等等。
针对这些问题,Cloud Spanner 可以很好解决,这是一个关系型数据库,支持 Schaema、ACID、标准的SQL。具备 NoSQL 数据库横向扩展的能力,全托管,没有计划内停机的时间,还提供高达99.999%的服务可用性保障。
来自于第三方调研机构 Enterprise Strategy Group,一个为期三年的对数据库成本分析。经过分析发现 Cloud Spanner 对比数据库本地分片。三年之内,整体拥有成本节约了78%,对比其他云厂商的类似的方案,也有37%的成本的节约。
最后我们来看一个客户案例。
Dragon Quest Wolk,勇者斗恶龙系列的 AR 版本。2019年9月发布的首周就有五百万的下载量,至今仍然每秒都有数亿好几千次的这种数据库的查询,运行在上百个这个cloud spanner 节点上。
为什么使用cloud spanner呢?
根据该客户自己的总结,主要是以下几点。
首先是从扩展性的方面,过去通过手工扩展,往往需要几个小时,甚至几天,现在只需鼠标点一点几分钟就可以扩展。
其次,稳定性。过去每个月至少有一次数据库停机,现在偶尔会有,但是也不是因为 Cloud Spanner 的问题。
最后,从开发者的角度。过去除了开发游戏还要负责处理多个数据库节点之间复杂的分布式事务,,以及数据一致性的问题。写出来的代码很难看懂。现在这些事情可以交给 Cloud Spanner 去做。开发者可以将更多的精力 Focus 在自己的游戏上,写出来的东西更加的简洁和易于维护。
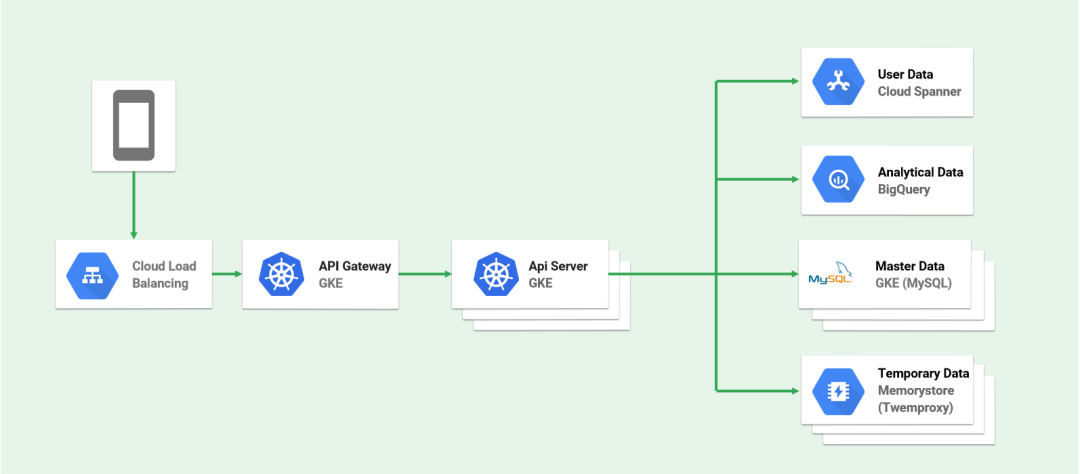
下图是Dragon Quest Wolk 的架构图。我们看右边的数据部分,用 Cloud Spanner 管理存储用户的数据,BigQuery 进行数据分析,一主多从的 My SQL 用来master 信息,即游戏中怪兽、道具的信息。用这个 Memorystore 即内存数据库将经常用到的查询 Cash 到里面,从而提高数据库的数据访问速度。
以上为今天的内容,下一次我们来聊一聊如何借助数据分析+AI 来进行游戏营销,掌控玩家行为。
如果大家关于今天的内容有什么问题,欢迎在评论区与我们交流互动~




