
Youtube 都在用的 Cloud Spanner 到底是“何方神圣”
数据库是应用程序运行过程中至关重要的一部分,Cloud Spanner 作为唯一一个企业级、全球分布和强一致性的企业级数据库服务,将关系数据库结构的优点与非关系型数据库的规模完美结合。更独特的是,Spanner 通常将事务、SQL 查询和关系结构与非关系或 NoSQL 数据库的可伸缩性相结合。
Cloud Spanner 是如何工作的?
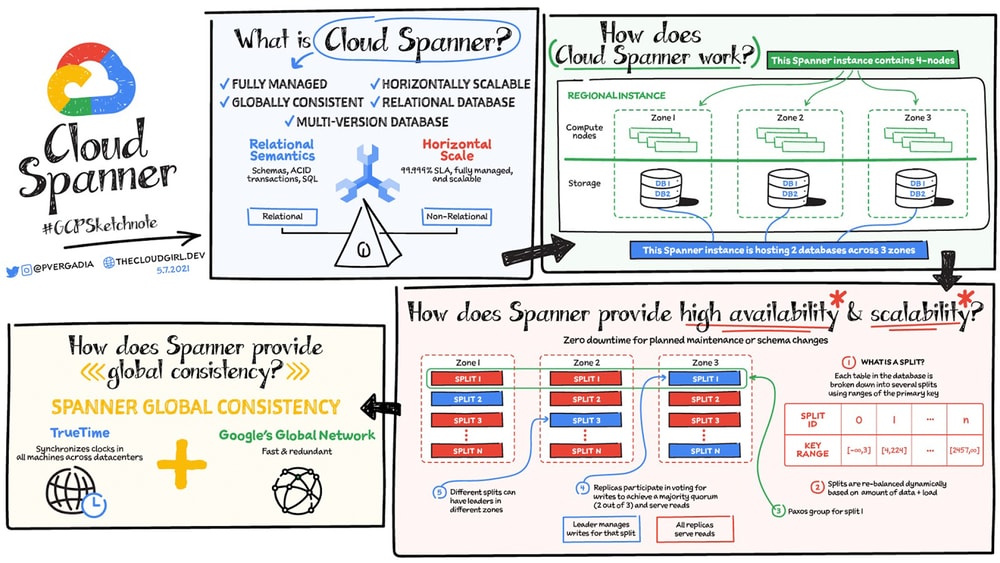
在图1中,可以看到一个四节点区域云 Spanner 实例,该实例托管两个数据库。节点是 Cloud Spanner 计算的量度标准。节点服务器提供读取和写入/提交事务请求,但它们不存储数据。每个节点在该区域的三个区域进行复制,数据库存储也在三个区域中复制。区域中的节点负责对其区域中的存储进行读写。数据存储在谷歌基础的巨像分布式复制文件系统中,当涉及到重新分配负载时,可提供巨大的优势,因为数据不链接到单个节点。如果一个节点或数据库发生故障,数据库仍然可用,由剩余的节点提供服务,无需手动干预来保持可用性。
Spanner 如何提供高可用性和可扩展性?
数据库中的每个表都按照主键排序存储,按主键的范围划分,即拆分。每个拆分完全有不同的 Spanner 节点独立管理,表的拆分次数根据数据量而变化,空表只有一次拆分。根据数据量和负载,拆分是动态重新平衡的。但是表和节点是跨三个区域复制的,这是如何工作的呢?
所以内容均在三个区域之间复制,拆分管理也是如此。拆分副本与一个跨区域的组(Paxos)相关联,使用 Paxos 共识协议,其中一个区域被认定为领导者。领导者负责管理该拆分的写入事务,而其他副本可用于读取。若领导者失败,则重新确定共识,并可能选择新的领导者。对于不同的拆分,不同的区域可以成为领导者,从而在 Spanner 计算节点之间分配领导角色。某个节点可以是领导者,也可以是其他拆分的副本。通过这种拆分、领导者、副本的分布式机制,Spanner 实现了高可用性与扩展性。
Spanner 中的读取类型
Cloud Spanner 中有两种读取类型。
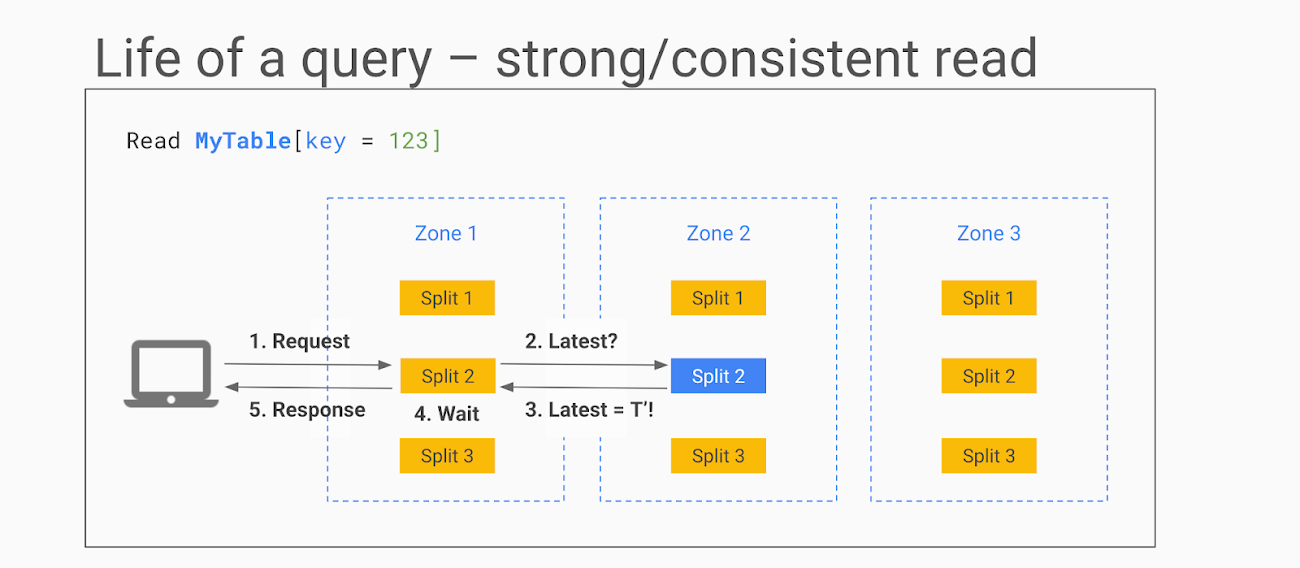
强读取- 在需要读取绝对最新值时使用。下面是它的工作原理:
- Cloud Spanner API 识别拆分,查找用于拆分的 Paxos 组,并将请求路由到其中一个副本(通常与客户端位于同一区域)在此示例中,请求发送到区域 1 中的仅读取副本;
- 如果可以读取,则向领导者请求复制副本,并要求提供此行上最新交易的 TrueTime 时间戳;
- 领导者响应,副本会将响应与其状态进行比较;
- 如果行是最新的,它可以返回结果。否则,它需要等待领导者发送更新;
- 响应被返回客户端。
在某些情况下,例如,当行刚刚更新,而读取请求正在传输中,副本的状态足够最新,它甚至不需要向领导者询问最新的事务。
过期读取— 当低读取延迟比获取最新值更重要时,就会使用过期读取,因此可以容忍某些数据过期。在过期读取中,客户端不会请求绝对的最新版本,而只是要求最新的数据(例如,最多为 n 秒)。如果陈旧系数至少为 15 秒,则大多数情况下,副本只需返回数据,甚至不询问领导者,因为其内部状态将显示数据足够最新。您可以看到,在每个读取请求中,无需行锁定 - 任何节点响应读取的能力是 Cloud Spanner 如此快速和可扩展的原因。
Spanner 如何提供全球一致性?
TrueTime 是跨多个数据中心在所有计算机中同步时钟的一种方式。该系统使用 GPS 和原子钟的组合,每个原子钟都针对另一个的故障模式进行矫正,将两个来源进行合并(当然使用多个冗余)为所有 Google 应用程序提供了准确的时间来源。但是,每个单台计算机上的时钟漂移仍然可能发生,即使每 30 秒同步一次,服务器时钟和参考时钟之间的差值也可以高达 2ms。漂移将看起来像一个锯牙图,不确定性增加,直到被时钟同步更正。由于 2ms 的持续时间相当长(至少在计算方面),TrueTime 将此不确定性作为时间信号的一部分。
如果您的应用程序需要一个高度可扩展的关系数据库,可以考虑 Cloud Spanner。要更深入地了解 Cloud Spanner ,请参考官方文档。
官方文档:https://cloud.google.com/spanner/docs




