
百分点是中国领先的数据智能技术企业,拥有完整的大数据和认知智能产品线,以及行业智能决策应用产品,同时创建了丰富的行业解决方案和模型库,拥有强大的行业知识图谱构建能力。目前已服务国内外10,000+企业与政府客户,致力于推进数据到知识再到智能决策的演进。
客户挑战
百分点认知智能实验室应用预训练语言模型的方法主要有两种:
一是通过互联网上开源的预训练语言模型,如 BERT 和 XLNet 等,并根据上游任务建立相应的模型进行 finetune;
二是在遇到对效果要求很高的 NLP 任务上,实验室会根据目标语料进行预训练语言模型的增量或重新训练,通过新生成的预训练模型,实验室在文本分类、信息抽取、问题等价性等方面取得重要的进展。
然而,预训练的语言模型也带来了一定的问题,在传统的 word embedding 加 LSTM 或 CNN 为主的模型训练当中,模型的参数很少会超过千万级,而这样的模型只用一块或几块 GPU 即可在短时间内完成训练。
相比之下,base 版本的 BERT 模型有1.5亿个参数,而 large 版本的则超过3亿,这样的模型即使仅仅根据任务 finetune 也可能需要数日,而重新训练则更是需要以月为单位计算。
计算成本开销的增大,不但增加了应用该模型的困难,同时也为 NLP 算法工程师的工作方式带来了一定的挑战。由于使用预训练语言模型需要经过大量的调参,所以这使得算法工程师的工作面临着两难的决策。
一方面,如果采用串行的方法进行调参,则 NLP 算法工程师需要花费大量的时间进行等待,从而严重降低了其单位时间的产出。另一方面,如果采用并行的方式进行调参,则消耗的算力会显著的增加。
为了应对这些挑战,WebEye 综合其技术能力、业务需求、成本考量、效率提升等因素,为百分点认知智能实验室推荐了 Cloud TPU 方案。
解决方案
- Cloud TPU 助力模型训练:
Cloud TPU,Tensor Processing Unit,Google 定制开发的专用集成电路 (ASIC),用于加速机器学习工作负载。TPU 的主要功能是矩阵运算,它是一个单线程芯片,不需要考虑缓存、分支预测、多道处理等问题的处理器,其可以在单个时钟周期内处理数十万次矩阵运算,而 GPU 在单个时钟周期内只可以处理数百到数千的计算。相比于 GPU,TPU 的实际运算表现要比 GPU 更加稳定,TPU 对于数据的读取也进行了大量的优化,所以当所涉及的运算包含大量的矩阵计算时,TPU 在训练的优势就显现出来了。
- 抢占式实例的高效利用:
云上资源的使用成本也是实验室考虑的一项重要因素。WebEye 建议客户在创建 TPU 实例时,选择抢占式实例,定时处理模型训练任务,充分利用资源,不仅极大节省了云服务成本,更提高了处理效率。
- Cloud Storage:
数据存储方面,考虑到本地存储的读取速度、稳定性问题,WebEye 推荐其使用 Cloud Storage。Cloud Storage 能通过优化 input pipline 来确保 TPU 的高性能。数据持久性和安全性方面,即便使用抢占式 TPU 实例,实例生命周期结束后,数据也不会丢失。
客户收益
TPU 在训练 BERT 模型中到底有怎样的优势呢?实验室分别就重新预训练语言模型和 finetune 语言模型的任务进行了比对。
他们采用了 500M 的文本语料,并根据主流的 BERT BASE 版模型的参数要求:首先将文本数据 mask 十遍产生预训练数据,然后采用了序列长度为128、12层、768维等参数进行 500K 步训练。
使用 TPU v2-8 进行计算并与主流 GPU Nvidia Tesla V100 从运算时间和花费上进行对比:
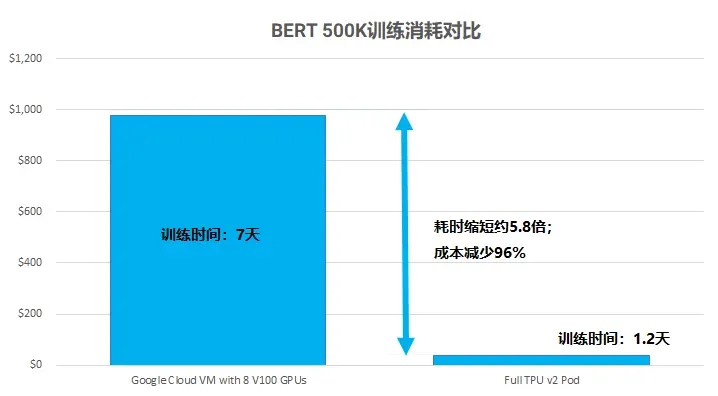
通过与主流的 GPU Tesla V100*8 对比发现,使用 GPU 进行训练花费了大约7天时间,而是用 TPU 进行训练仅需要了1.2天即可完成。同时,在总费用成本上也是大量的缩减。TPU 在 BERT 预训练模型的运算时间和总成本上完胜了当前的主流的 GPU。
实验室负责人 Dr.Wang:“TPU 的超高效率和低廉价格将神经网络计算变得更加亲民了,TPU 可以从根本解决了中小公司算力要求高但经费不足的顾虑,曾经那种需要几十台 GPU 几天时间的 BERT 预训练由一个 TPU 一天可以轻松解决。这让所有的中小型企业也可以拥有之前所缺少的强大算力。”
使用产品
- Compute Engine
- Cloud TPU
- Cloud Storage




