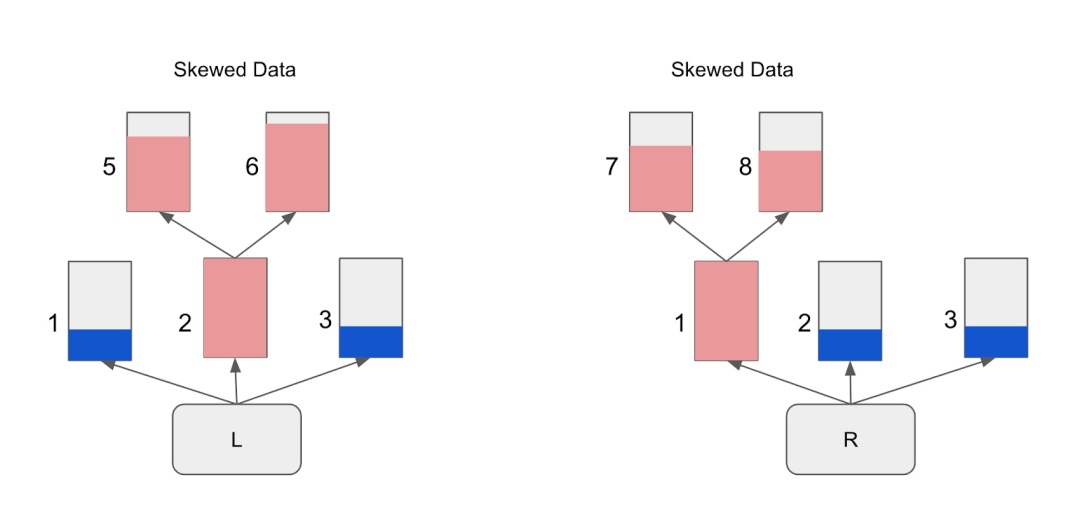
对客户而言,BigQuery 可以为他们解决一些困难的问题——从 BigQuery 机器学习(BQML)SQL 将数据分析师转变为数据科学家,到使用 SEARCH 功能解锁非结构化数据上的特别文本搜索的富文本分析。BigQuery 易用性的一个关键原因是其底层的无服务器体系结构,它可以增强分析查询的性能,同时使它们随着时间的推移运行得更快,而无需更改一行 SQL。在本博客中,我们揭开帷幕,分享 BigQuery 无服务器架构背后的魔力,如存储和查询优化以及生态系统改进,以及它们如何使客户能够在 BigQuery 中无限制地工作,以运行他们的数据分析、数据工程和数据科学工作负载。BigQuery 将表数据存储在一个名为 Capacitor 的列式文件存储中。这些电容器文件最初具有数百兆字节的固定文件大小,以支持 BigQuery 客户的大型数据集。更大的文件大小通过减少查询必须扫描的文件数量,实现了对 PB 级数据的快速高效查询。但是,随着从传统数据仓库转移过来的客户开始引入更小的数据集(大约为千兆字节和兆兆字节),默认的“大”文件大小不再是这些较小表格的最佳形状因素。BigQuery 团队认识到该解决方案需要针对大小查询工作负载的用户进行扩展,因此提出了针对电容器文件的自适应文件大小调整概念,以提高小型查询性能。BigQuery 团队开发了一种自适应算法,可以动态地为在 BigQuery 存储中创建的新表分配适当的文件大小,从几十到几百兆字节不等。对于现有的表,BigQuery 团队添加了一个后台流程,将现有的“固定”文件大小的表逐渐迁移到自适应表中,将客户的现有表迁移到性能高效的自适应表中。如今,后台电容器过程继续扫描所有表的增长,并动态调整它们的大小,以确保最佳性能。如果工作负载必须扫描所有文件中的每个表,那么从存储文件中维护的 BigQuery 表中读取和写入可能会很快变得效率低下。与大多数大型数据处理系统一样,BigQuery 已经开发了关于文件内容的丰富信息存储,这些信息存储在每个电容器文件的头中。这些关于数据的信息称为元数据,允许 BigQuery 中的查询规划、流式传输和批处理、事务处理和其他读写过程快速识别存储中要执行必要操作的相关文件,而不会浪费时间读取不相关的数据文件。但是,虽然读取小表的元数据相对简单快速,但大型(PB 级)事实表可以生成数百万个元数据条目。为了让这些查询快速生成结果,查询优化器需要一个高性能的元数据存储系统。基于他们在2021 VLDB 论文“大元数据:当元数据是大数据时”中提出的概念,BigQuery 团队开发了一个分布式元数据系统,称为 CMETA,该系统具有细粒度列和块级元数据,能够支持非常大的表,并且作为系统表进行组织和访问。当查询优化器接收到查询时,它会重写查询,以将半联接(WHERE EXISTS 或 WHERE IN)应用于 CMETA 系统表。通过将元数据数据查找添加到查询谓词中,查询优化器显著提高了查询的效率。除了管理 BigQuery 基于电容器的存储的元数据外,CMETA 还通过 BigLake 扩展到外部表,提高了大量 Hive 分区表的查找性能。VLDB 论文中分享的结果表明,对于使用 CMETA 元数据系统在100GB到10TB范围内的表上进行查询,查询运行时可以加速5倍到10倍。BigQuery 有一个内置的存储优化器,可以使用各种技术持续分析和优化存储在电容器内存储文件中的数据:Compact 和 Coalesce:BigQuery 支持使用 SQL 或 API 接口的快速 INSERT。最初将数据插入表时,根据插入的大小,可能会创建过多的小文件。Storage Optimizer 将这些单独的文件中的许多合并为一个文件,从而可以在不增加元数据开销的情况下高效地读取表数据。随着时间的推移,用于存储表数据的文件可能没有达到最佳大小。存储优化器分析这些数据,并将文件重写为大小合适的文件,以便查询能够扫描适当数量的这些文件,并最有效地检索数据。为什么合适的尺寸很重要?如果文件太大,那么从较大的文件中消除不需要的行会有开销。如果文件太小,那么在读取和管理正在读取的大量小文件的元数据时会有开销。集群:具有用户定义的列排序顺序的表称为集群列;使用多列对表进行集群时,当 BigQuery 将数据排序并分组到存储块中时,列顺序决定哪些列优先。BigQuery 集群只扫描基于集群列而不是整个表或表分区的相关文件和块,从而加速按集群列筛选或聚合的查询。随着集群表中数据的变化,BigQuery 存储优化器会自动执行隐式处理,以确保一致的查询性能。当查询开始在 BigQuery 中执行时,查询优化器会将查询转换为执行图,并将其分解为多个阶段,每个阶段都有步骤。BigQuery 使用动态查询执行,这意味着执行计划可以动态演变,以适应不同的数据大小和密钥分布,从而确保快速的查询响应时间和高效的资源分配。当查询大型事实表时,数据极有可能出现偏斜,这意味着数据在某些关键值上不对称分布,从而造成数据的不均衡分布。因此,与正常数据相比,对偏斜事实表的查询可能会导致更多的偏斜数据记录。当查询引擎将工作分配给工作人员以查询倾斜的表时,某些工作人员可能需要更长的时间来完成任务,因为某些键值有多余的行,即倾斜,从而导致工作人员的等待时间不均衡。让我们考虑一下可能在分布中显示偏斜的数据。板球是一项国际团体运动。然而,它只在世界上的某些国家流行。如果我们按国家保留一份板球迷名单,数据将显示,该名单偏向于国际板球理事会正式成员国的球迷,并不是在所有国家都平均分布。传统的数据库试图通过维护数据分布统计来处理这一问题。然而,在现代数据仓库中,数据分布可能会迅速变化,数据分析师可能会驱动越来越复杂的查询,从而使这些统计数据过时,从而变得不那么有用。根据在联接列上查询的表,偏斜可能在联接左侧或右侧引用的表列上。根据检测到数据偏斜的位置,将更多的工作人员容量分配给联接的左侧或右侧(任务2中左侧有数据偏斜;任务1中右侧有数据偏斜)
BigQuery 团队通过开发连接偏斜处理技术来解决数据偏斜问题,该技术通过检测数据偏斜并按比例分配工作,以便分配更多的工作人员来处理偏斜数据上的连接。在处理联接时,查询引擎会不断监视联接输入中是否存在扭曲的数据。如果检测到偏斜,查询引擎将更改计划以处理偏斜数据上的联接。查询引擎将进一步拆分偏斜的数据,在偏斜和非偏斜的数据之间创建相等的处理分布。这确保了在执行时,处理具有数据偏斜的表中的数据的工作人员根据检测到的偏斜按比例分配。这允许所有工作人员同时完成任务,从而消除了由于数据失真而导致的等待延迟,从而加快了查询运行时间。BigQuery 关于配额和查询作业限制的文档指出:“您的项目最多可以运行100个并发交互查询。”BigQuery 使用默认的并发设置100,因为它满足了99.8%客户工作负载的要求。由于这是一个软限制,管理员总是可以通过请求进程来增加这个限制,以增加最大并发性。为了支持不断扩大的工作负载范围,如数据工程、复杂分析、Spark 和 AI/ML 处理,BigQuery 团队开发了带有查询队列的动态并发,以消除对并发的所有实际限制,并消除管理负担。查询队列的动态并发是通过以下功能实现的:1.动态最大并发设置:默认情况下,当客户将目标并发设置为零时,他们开始获得动态并发的好处。BigQuery 将根据预留大小和使用模式自动设置和管理并发。需要手动覆盖选项的经验丰富的管理员可以指定目标并发限制,该限制将取代动态并发设置。请注意,目标并发限制是保留中可用插槽的函数,管理员指定的限制不能超过这个值。对于按需工作负载,此限制是动态计算的,管理员无法配置。2.排队等待超过并发限制的查询:BigQuery 现在支持查询队列,以在峰值工作负载生成超过最大并发限制的一连串查询时处理溢出情况。启用查询队列后,BigQuery 最多可以对1000个交互式查询进行排队,这样它们就可以被安排执行,而不是像以前那样由于并发限制而被终止。现在,用户不再需要扫描空闲时间段或低使用率时间段来优化何时提交工作负载请求。BigQuery 会自动运行它们的请求,或者将它们安排在队列中,以便在当前运行的工作负载完成后立即运行。大多数分布式处理系统在成本(查询硬盘上的数据)和性能(查询内存中的数据)之间进行权衡。BigQuery 团队认为,用户可以同时拥有低成本和高性能,而不必在两者之间做出选择。为了实现这一点,该团队开发了一个名为 Colossus Flash cache 的分解中间缓存层,该层在闪存中为主动查询的数据维护缓存。根据访问模式,底层存储基础设施将数据缓存在巨像闪存中。通过这种方式,查询很少需要转到磁盘来检索数据;从 Colossus Flash Cache 快速高效地提供数据。BigQuery 通过在内存中执行查询来实现其高度可扩展的数据处理能力。这些内存中操作从磁盘中获取数据,并将查询处理各个阶段的中间结果存储在另一个名为Shuffle的内存中分布式组件中。包含包含公共表表达式(CTE)的 WITH 子句的分析查询通常通过多个子查询引用同一个表。为了解决这个问题,BigQuery 团队在查询优化器中建立了一个重复的 CTE 检测机制。该算法大大减少了资源使用,允许在查询之间共享更多的混洗容量。为了进一步帮助客户了解他们的 shuffle 用法,该团队还将 PERIOD_SHOFFLE_RAM_usage_RATIO 指标添加到 JOBS INFORMATION_SCHEMA 视图和管理资源图表中。由于这些改进,您应该会看到更少的 Resource Exceeded 错误,并且现在有了一个跟踪指标,可以采取先发制人的措施来防止过度的 shuffle 资源使用。BigQuery 用户体验到的性能改进不仅限于 BigQuery 的查询引擎。我们知道,客户将 BigQuery 与其他云服务一起使用,以允许数据分析师使用他们的 BigQuery 数据从其他数据源获取或查询其他数据源。为了实现更好的互操作性,BigQuery 团队与其他云服务团队密切合作进行各种集成:1.BigQuery JDBC/ODBC 驱动程序:新版本的 ODBC/JDBC 驱动通过在后台处理身份验证令牌刷新,支持使用 OAuth 2.0(OAuthType=1)进行更快的用户帐户身份验证。2.BigQuery with Bigtable:Cloud Bigtable to BigQuery 联盟的 GA 版本支持下推特定行键的查询,以避免完整的表扫描。3.BigQuery with Spanner:现在,BigQuery 中针对 Spanner 的联合查询允许用户指定执行优先级,从而使他们能够控制联合查询在以高优先级执行时是否应与事务流量竞争,或者是否可以以低优先级设置完成。4.带有 Pub/Sub 的 BigQuery:BigQuery 现在支持通过专门构建的“BigQuery 订阅”直接接收 Pub/Sub 事件,该订阅允许将事件直接写入 BigQuery 表。5.带有 Dataproc 的 BigQuery:BigQuery 的 Spark 连接器支持 DIRECT 写入方法,使用 BigQuery Storage write API,避免了将数据写入云存储的需要。
返回全部