
全网最全部署教程 | Mistral引领大型语言模型新篇章
在科技的浪潮中,Mistral大型语言模型犹如一颗璀璨的明星,正在引领自然语言处理(NLP)领域的新风潮。今天,就让我们一起揭开它神秘的面纱,探索它背后的魅力。
Mistral-7B,这款拥有70亿参数的模型,凭借卓越的性能和效率,在众多评估基准上脱颖而出。它不仅是技术的结晶,更是智慧的体现。而Mistral-7B-Instruct更是经过精心微调,擅长遵循指令,为用户带来更加智能、便捷的体验。
此外,Mistral AI还推出了Mixtral 8x7B模型,这款混合专家大型语言模型拥有46.7B参数,支持多语言处理,性能卓越。它的出现,让我们看到了NLP领域的无限可能。
Mistral大型语言模型以其卓越的性能和独特的设计,正在开启智能时代的新篇章。
那么如何部署此模型呢?
1. Notebook
单击打开笔记本,使用Colab中的Mistral notebook在模型上部署和运行推理,适用于测试等轻量级环境。
2. 部署至服务器
点击部署,部署至GPU服务器(Compute Engine/GKE)上,适用于生产环境。
部署步骤
1. 模型位置
首先导航至Vertex AI的Model Garden中,搜索Mistral模型,并单击进入。
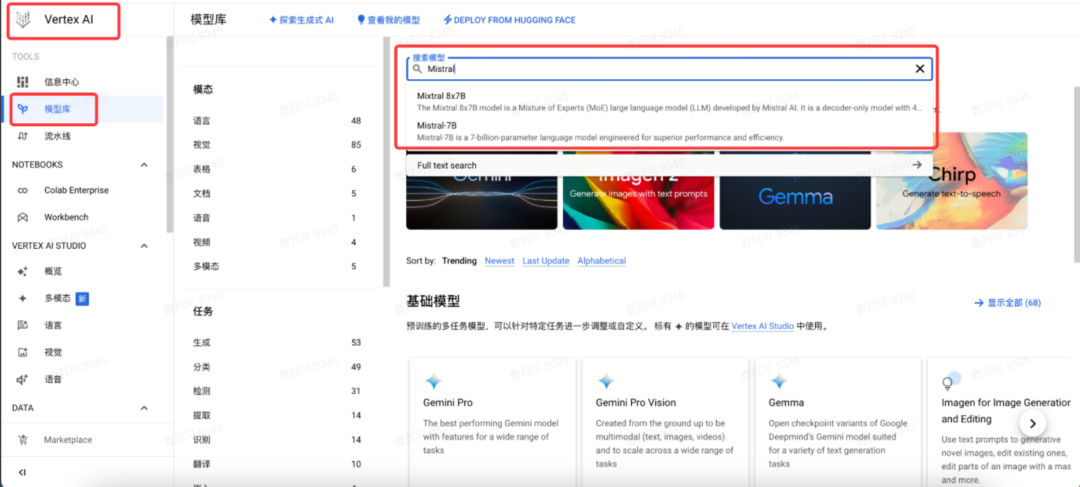
2. 一键部署
注意:此部署方式无法扩缩,生产环境建议参考下文自定义部署步骤。
进入模型后,单击部署,打开配置界面,按需求修改配置,并选择相应的区域,确认无误后即可点击部署。部署过程约需30分钟。
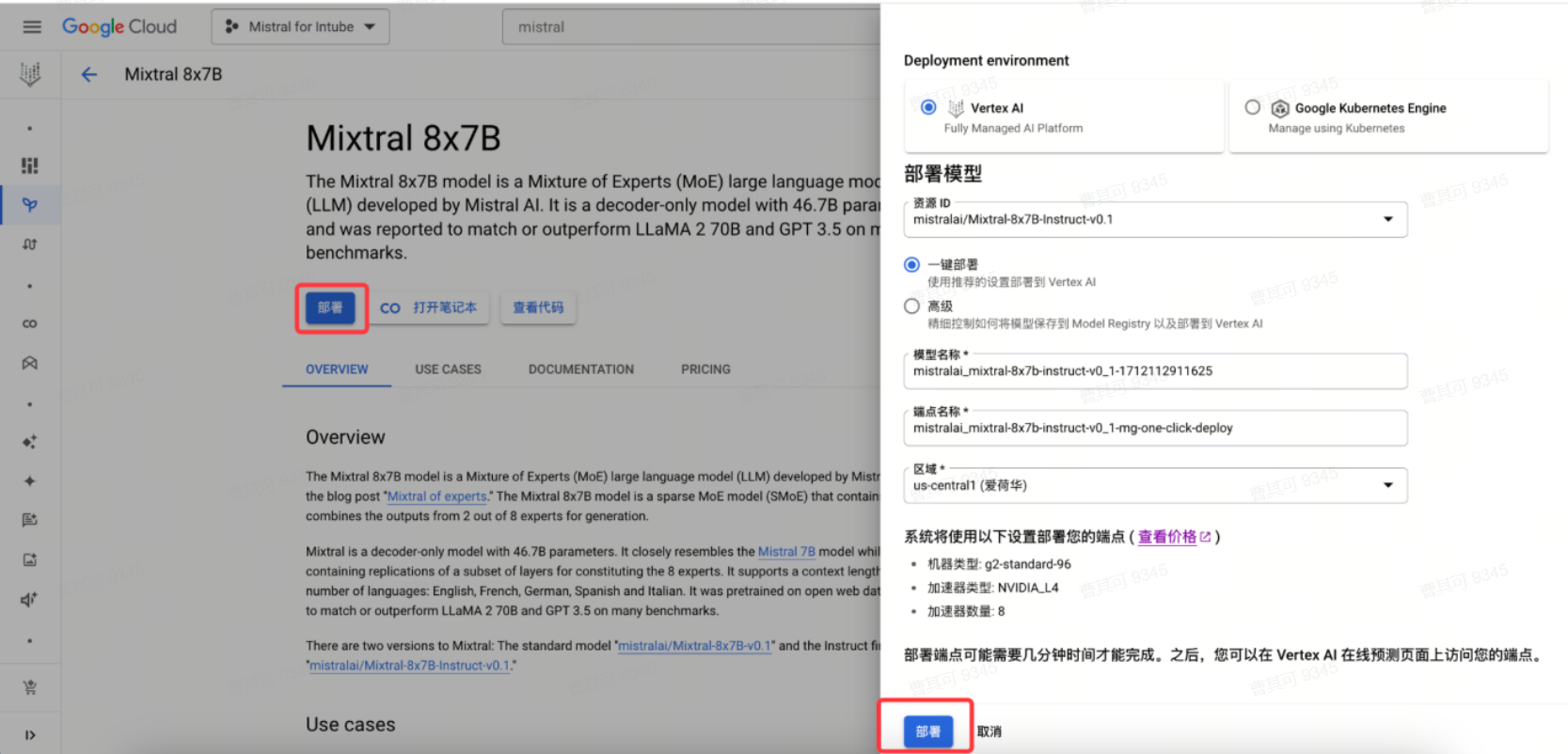
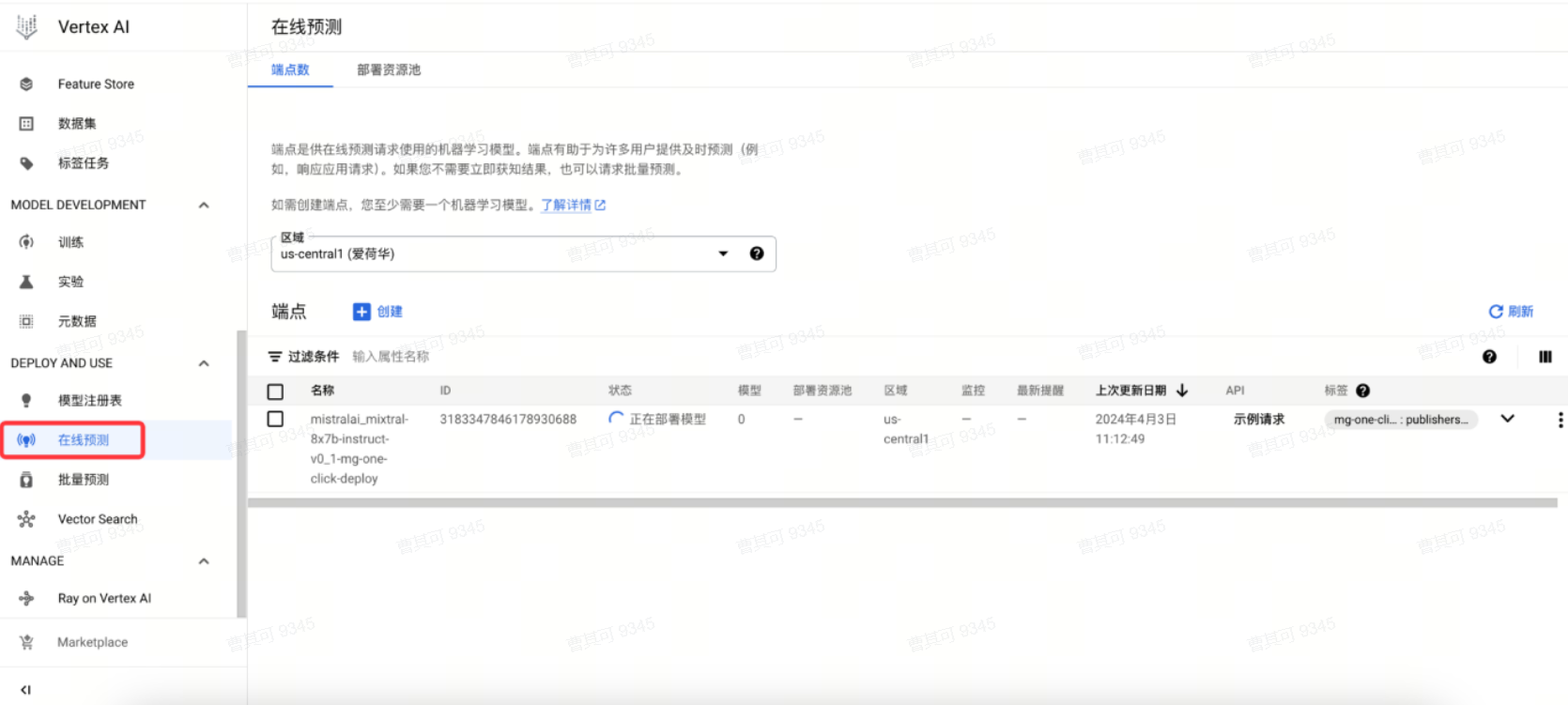
部署过程中,可导航至在线预测查看部署进度。
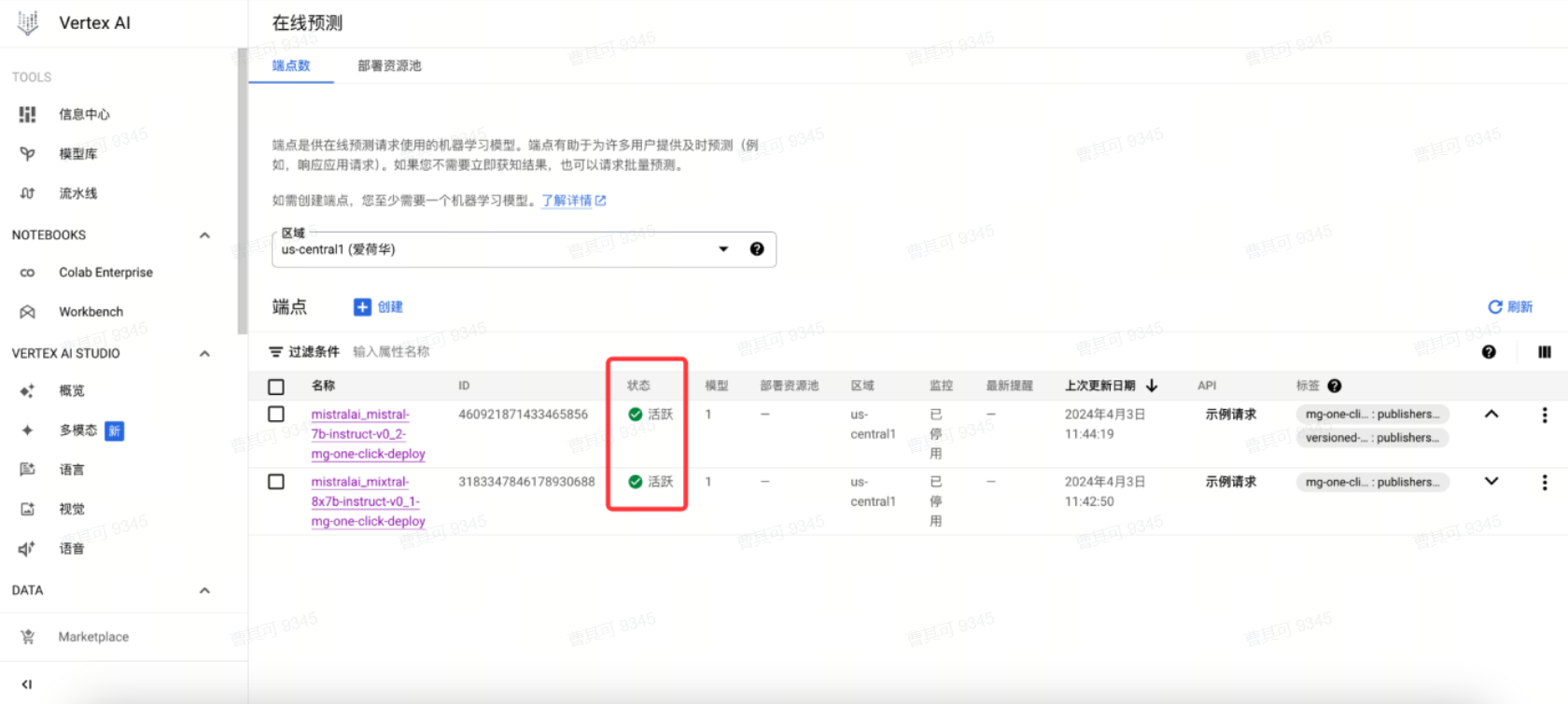
部署成功。
注意:
一键部署模式,计算节点默认下限为1,上限为1,如需调整,参考下文自定义部署。
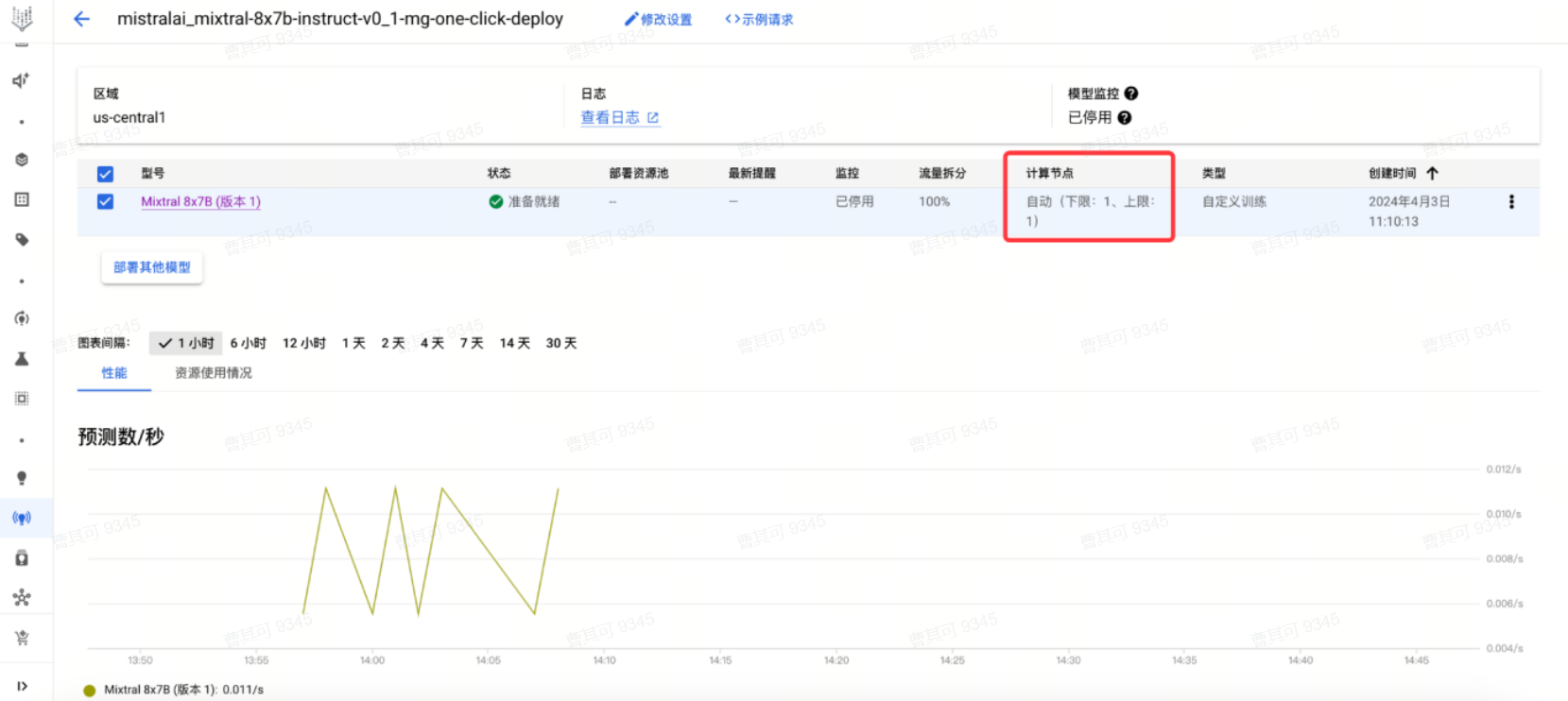
自定义部署
点击高级部署。
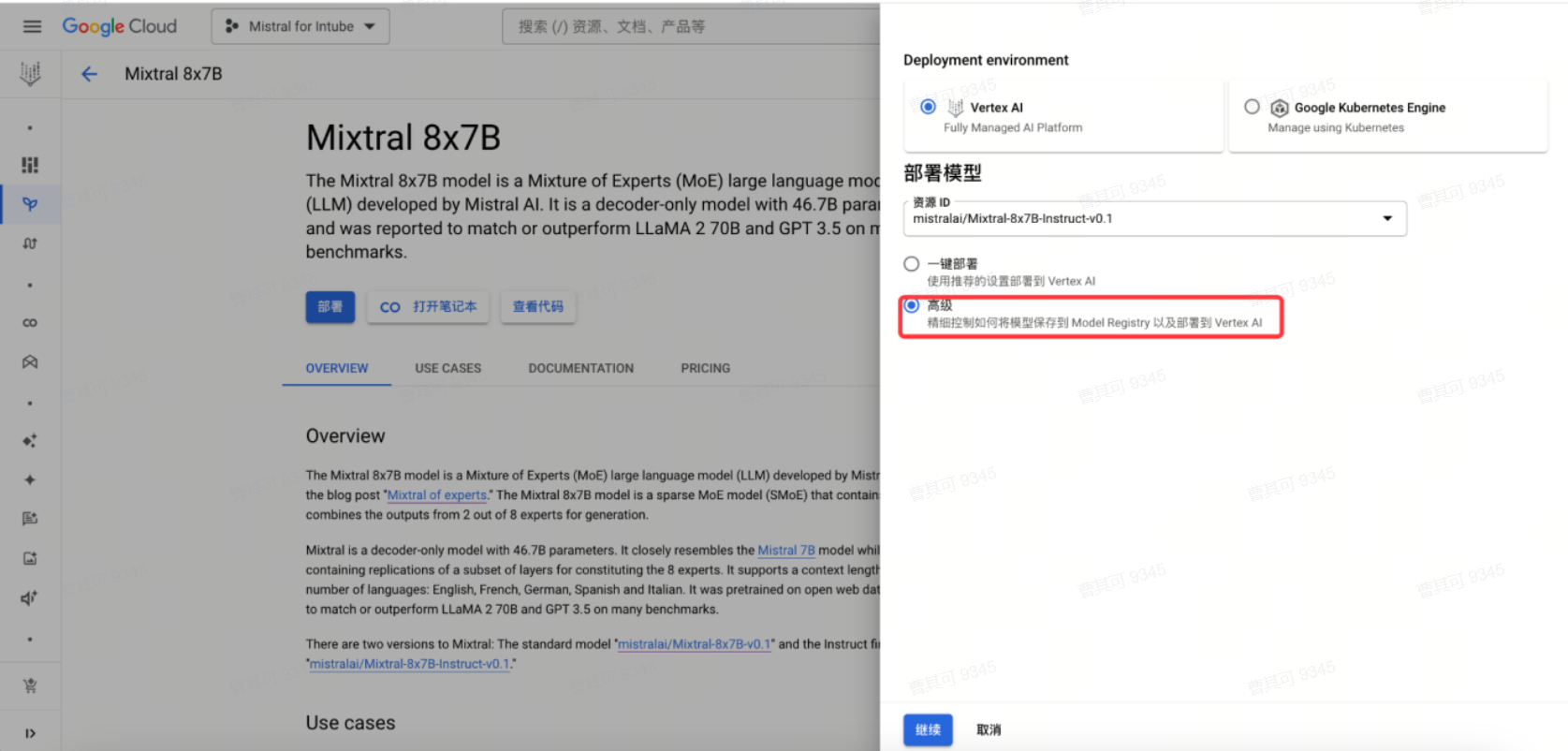
首先将要部署的模型版本保存至Model Registry。
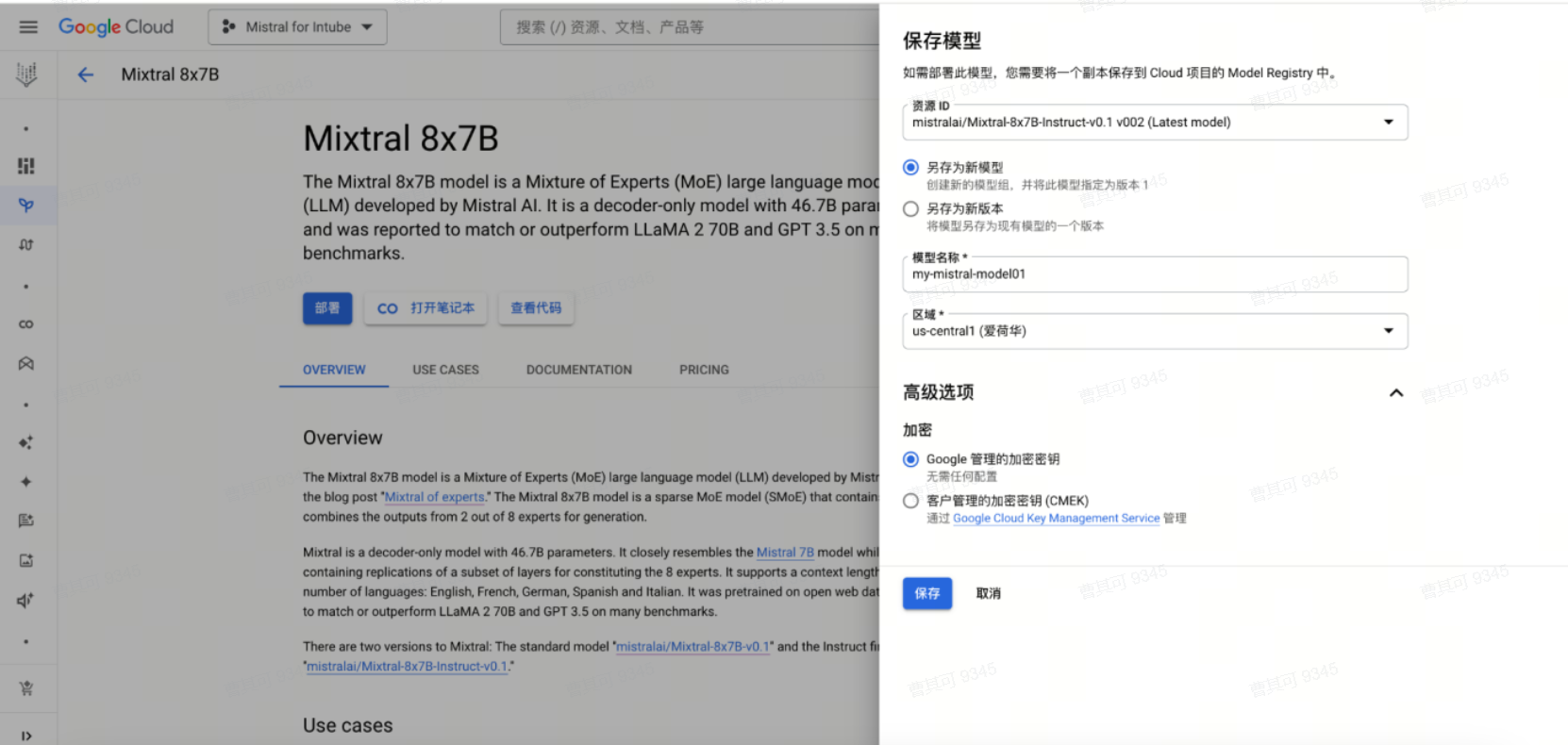
点击保存后,定义端点。
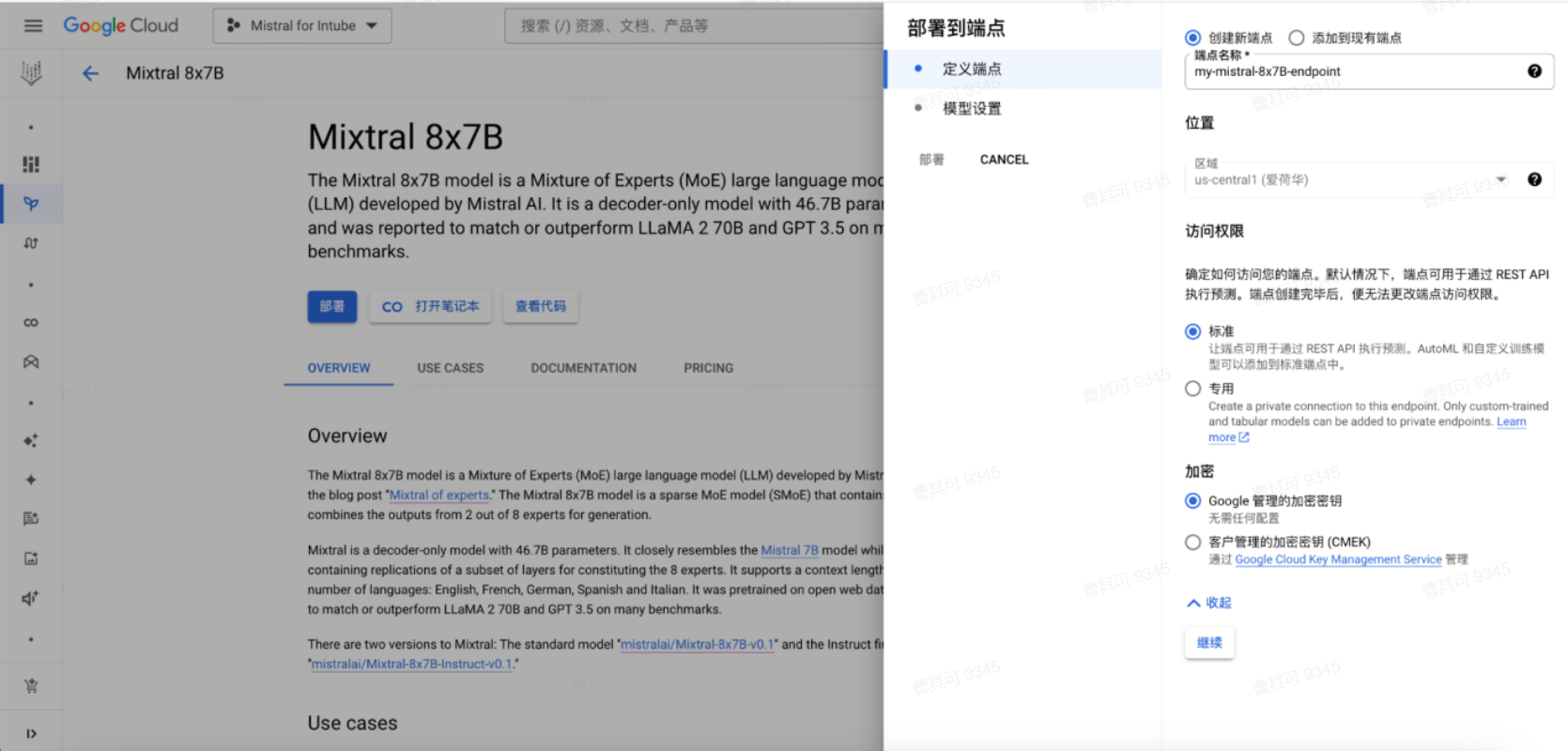
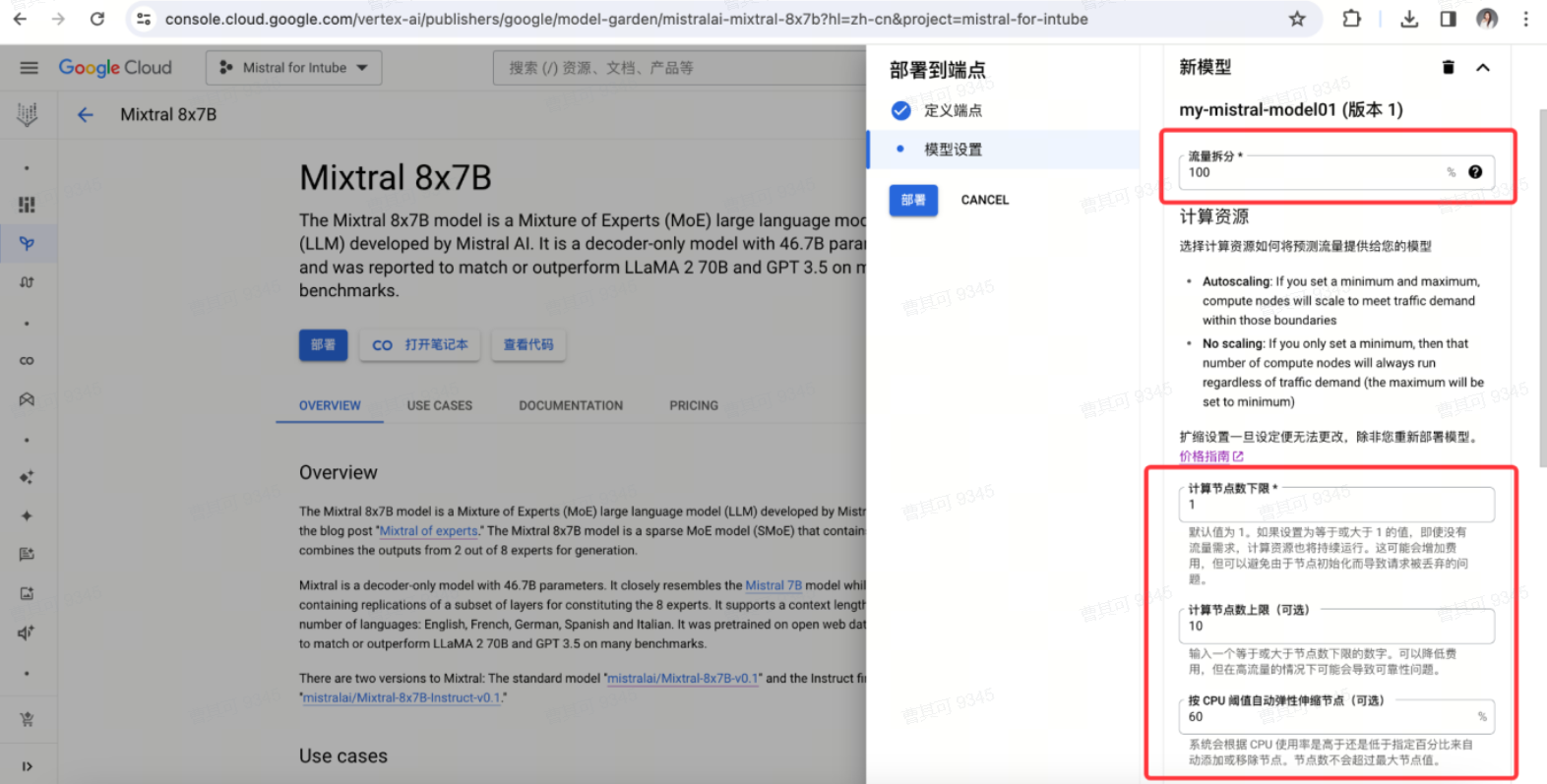
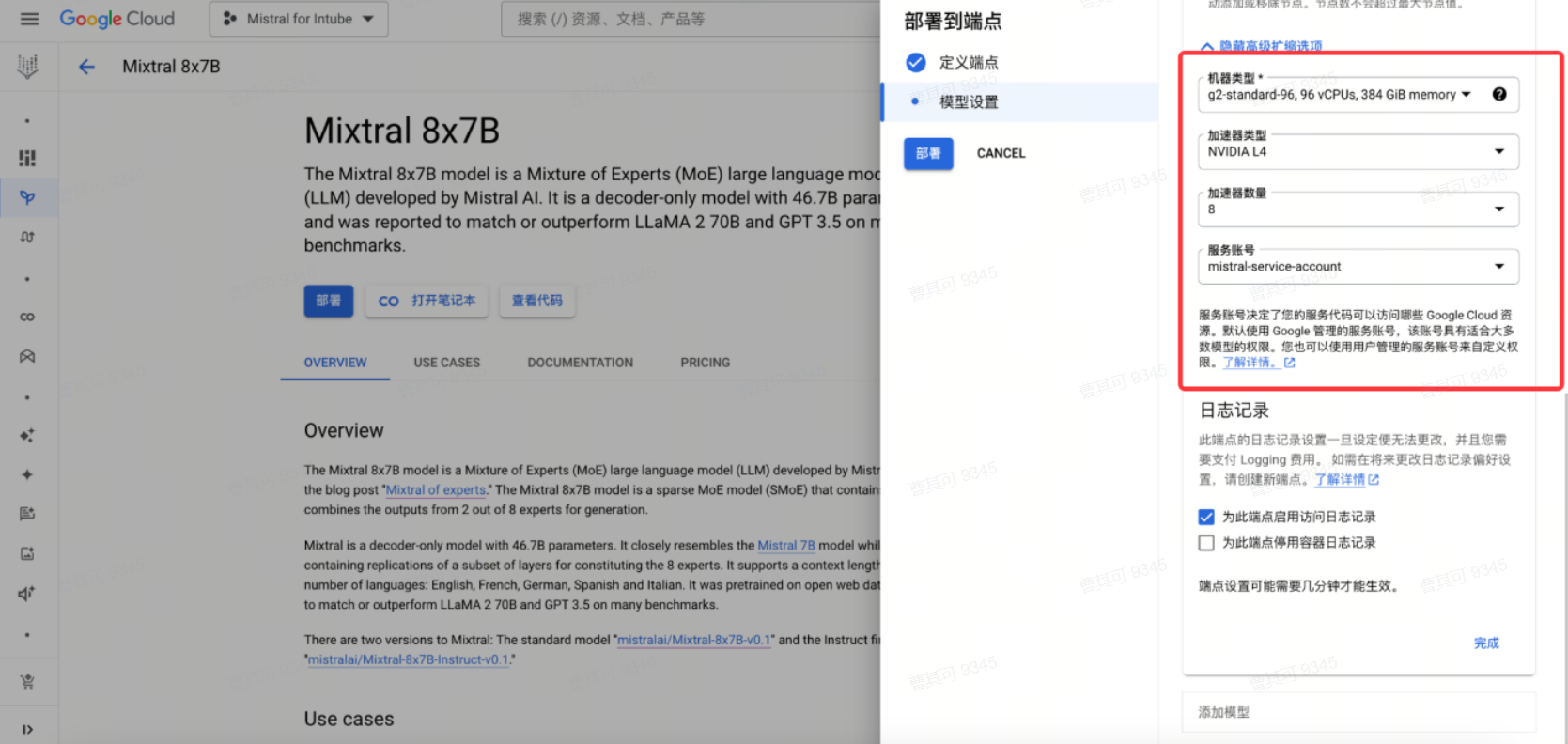
在模型设置中,根据具体需求,对流量拆分、节点上下限、伸缩阈值、机器类型、服务账号进行修改后,点击部署。
机器类型建议:

注意:
● 扩缩设置一旦设定便无法更改,除非重新部署模型。
● 关于流量拆分:一个端点上,可以部署多个模型;应确定将多少发送到端点的传入请求流量定向到此模型。如果端点上只有唯一一个模型,必须将流量分配比例设为 100%。如果向端点添加了更多的模型,可以稍后更新流量分配比例。
使用
此模型支持两种请求方式:Restful API与Python SDK,可通过示例请求进行查看。
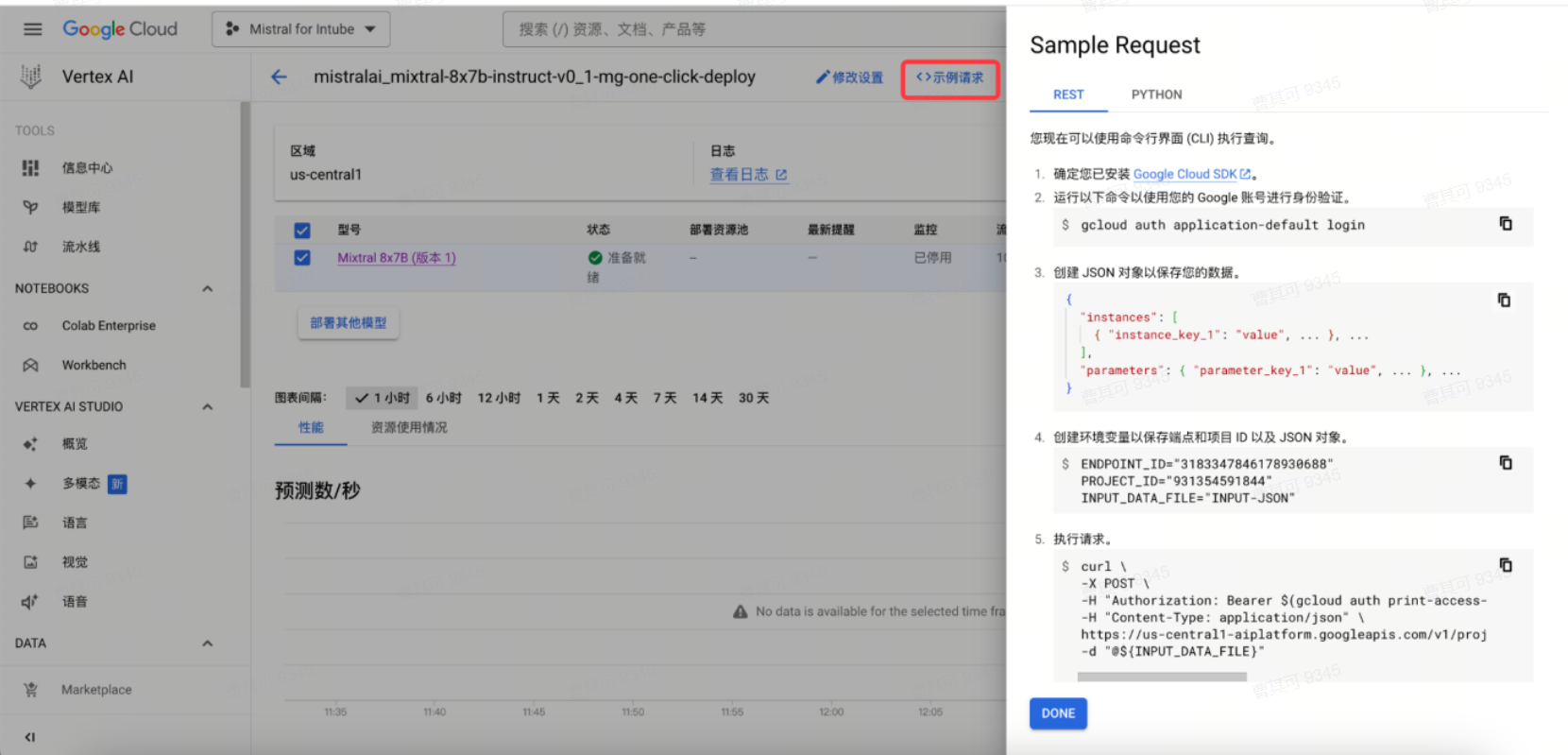
1. Restful API使用方式
● 首先确保环境已安装Google Cloud SDK
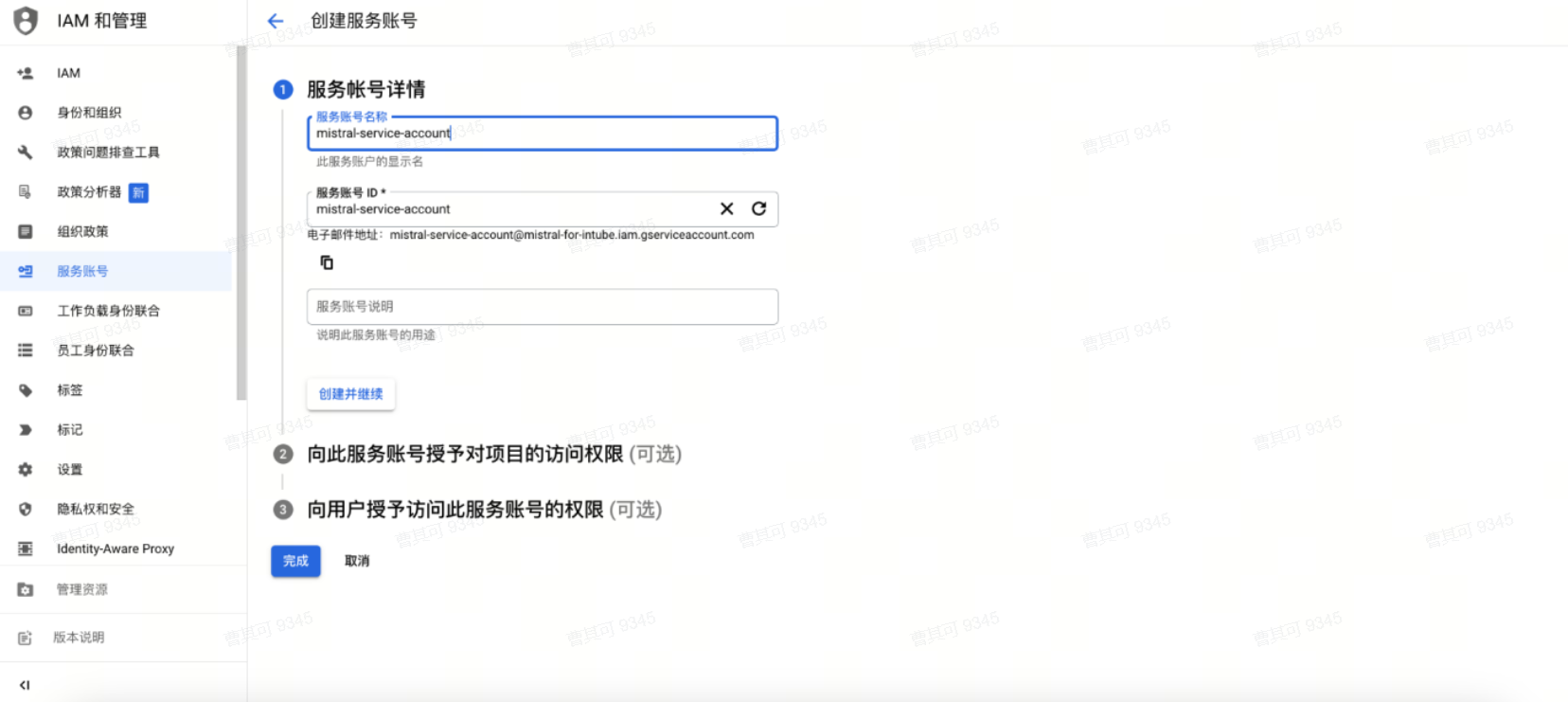
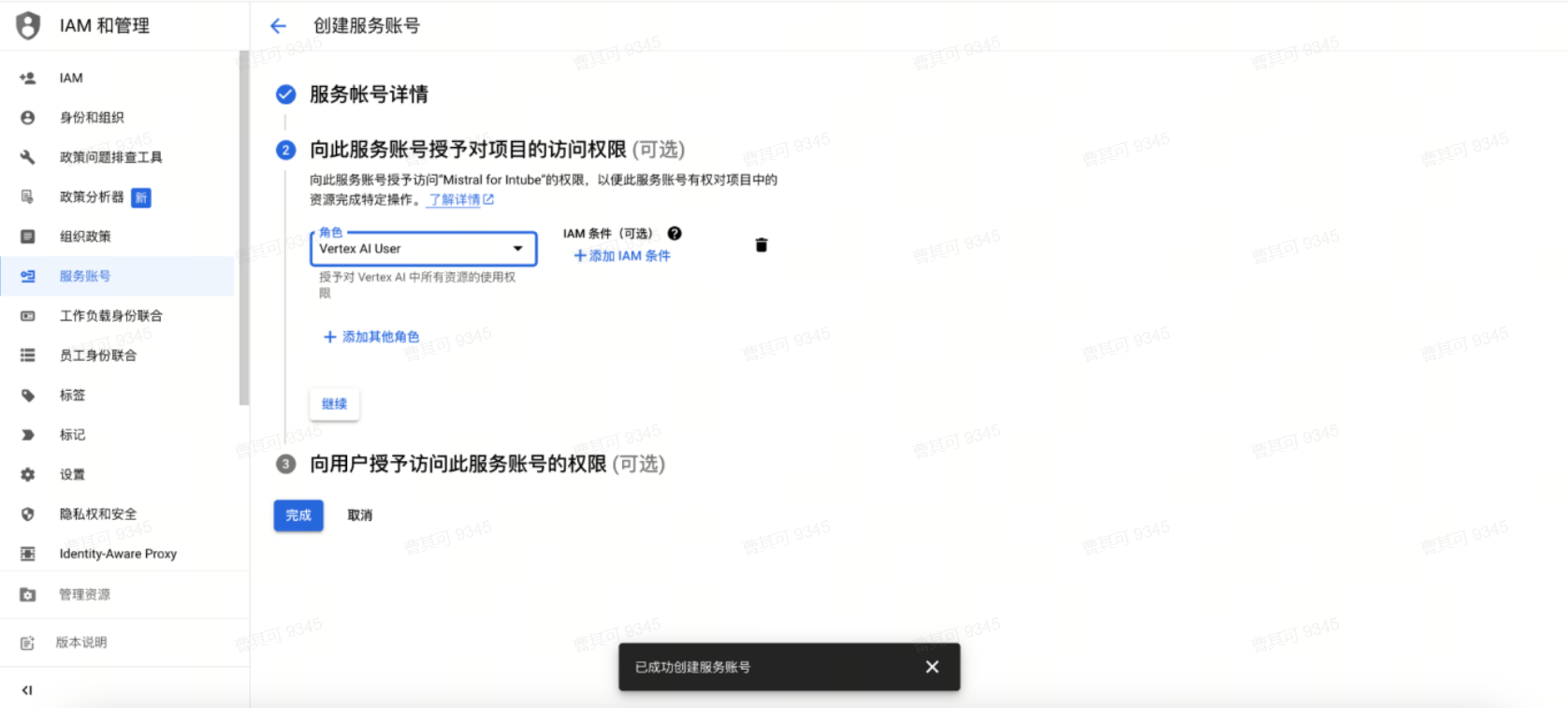
● 创建服务账号,并授予Vertex AI User角色
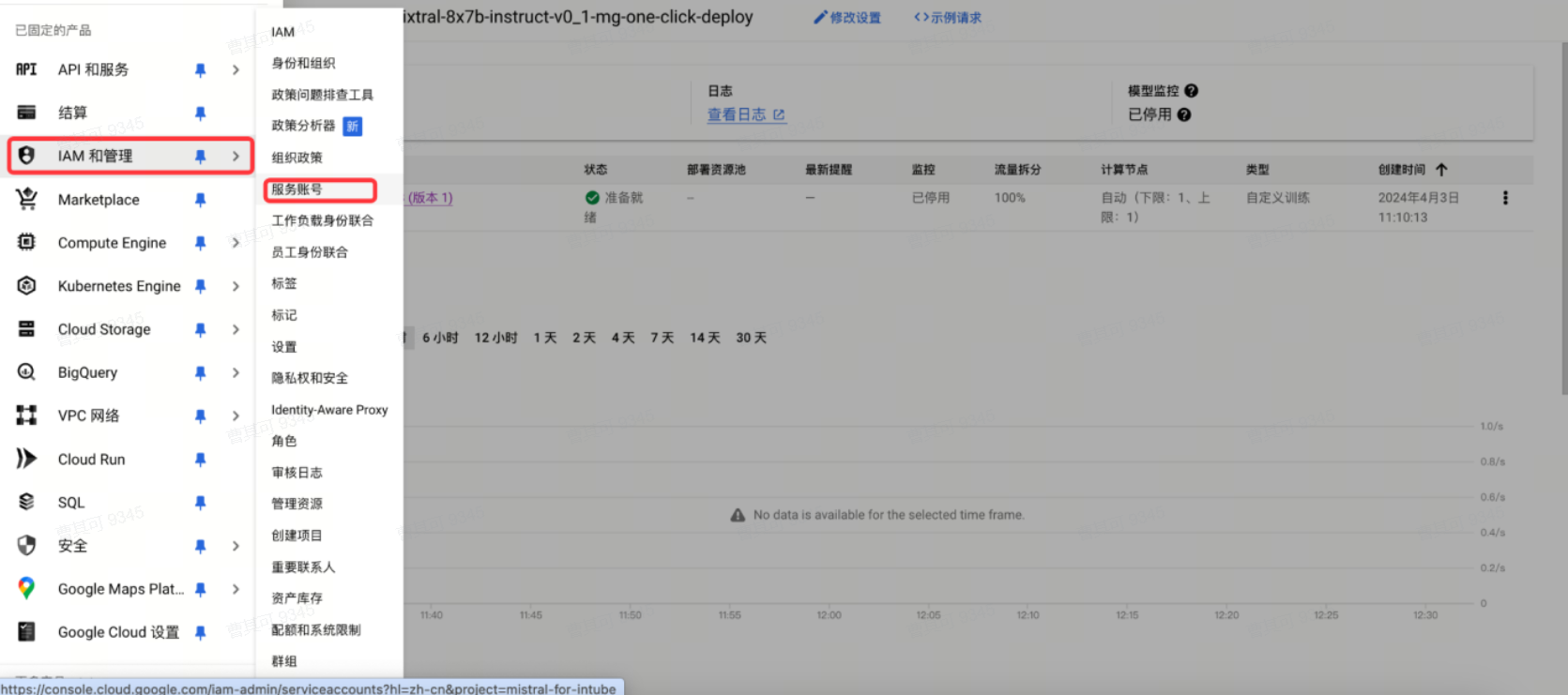
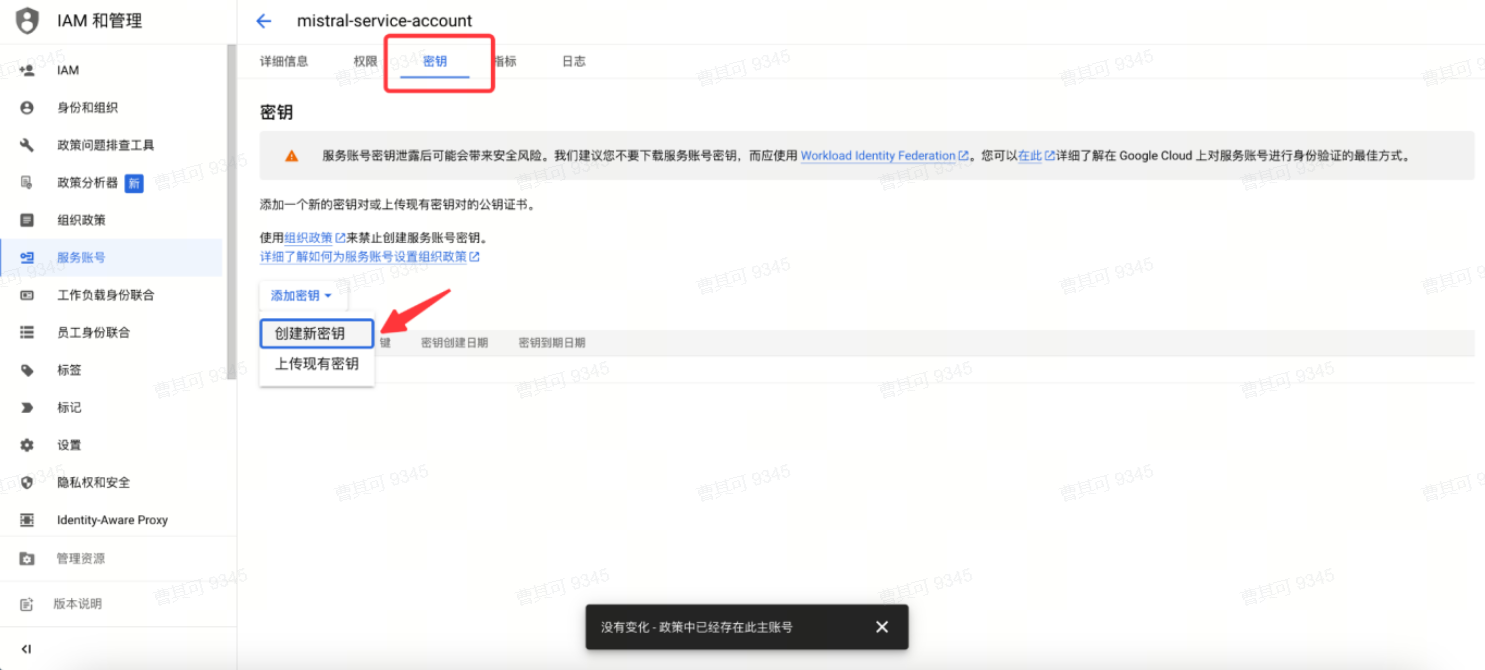
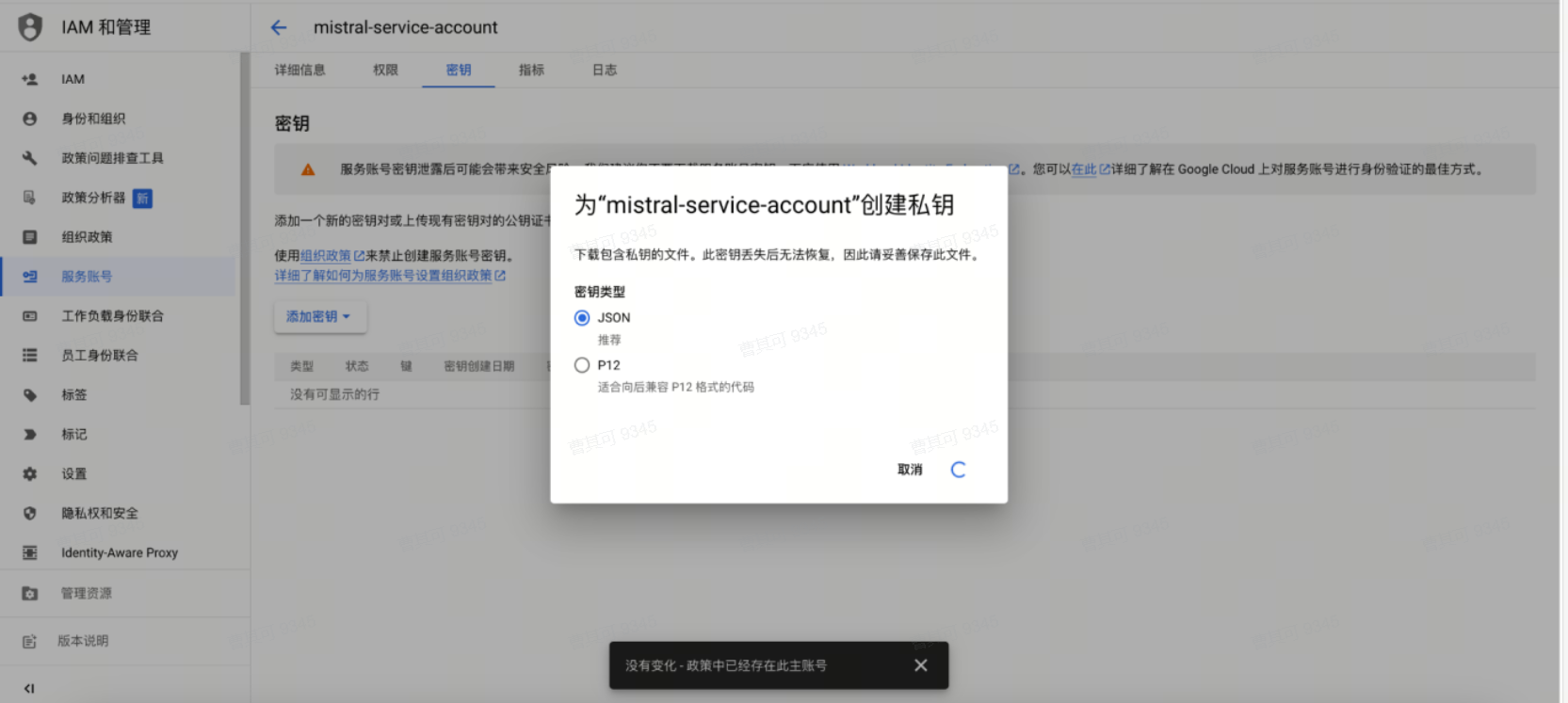
● 创建json格式密钥文件
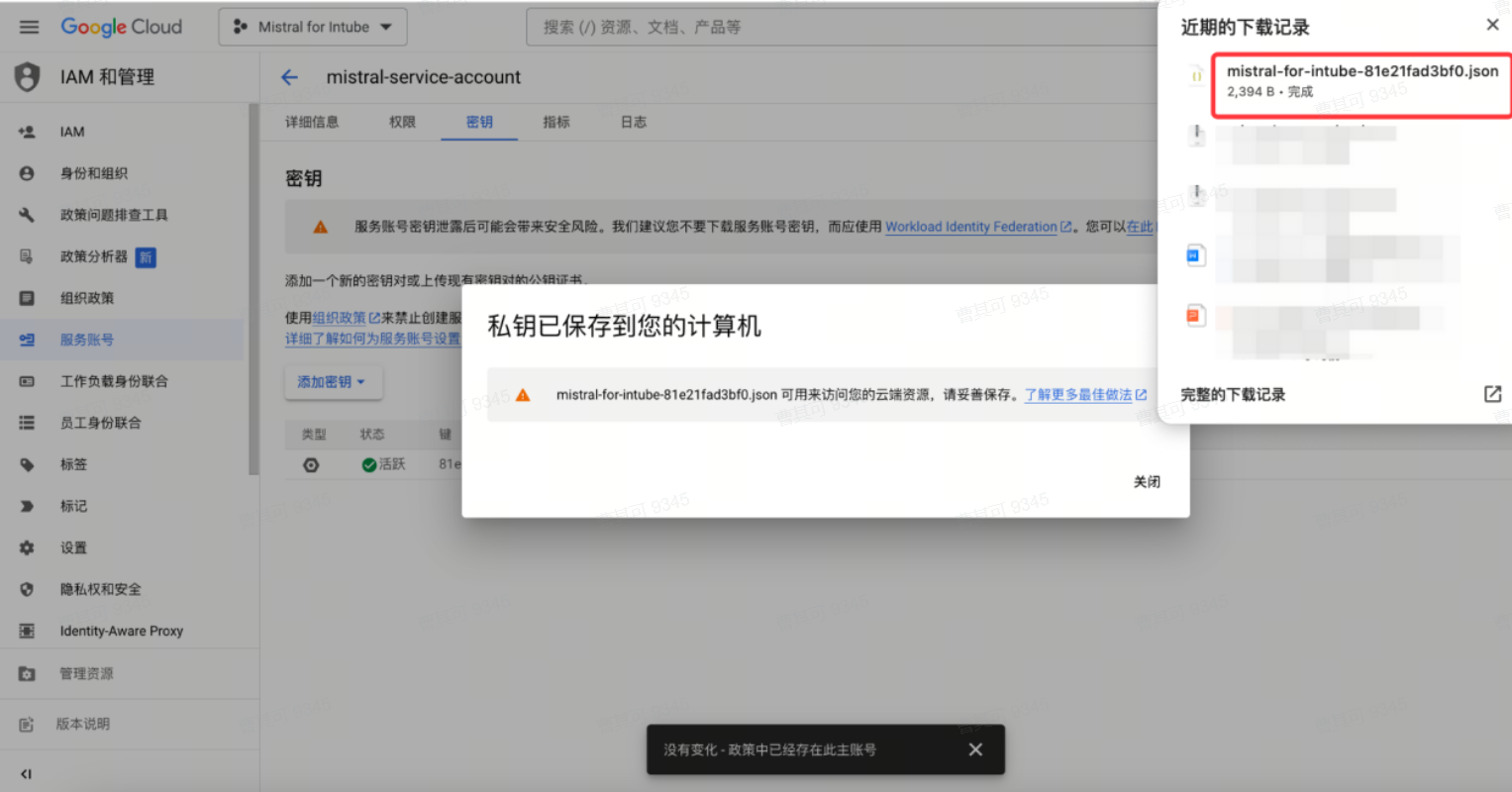
● 将密钥上传环境,并设置环境变量
将环境变量 GOOGLE_APPLICATION_CREDENTIALS 设置为包含服务帐号密钥的 JSON 文件的路径。
示例:将 [PATH] 替换为包含您服务帐号密钥的 JSON 文件的路径。
export GOOGLE_APPLICATION_CREDENTIALS="/PATH/xxxx.json"
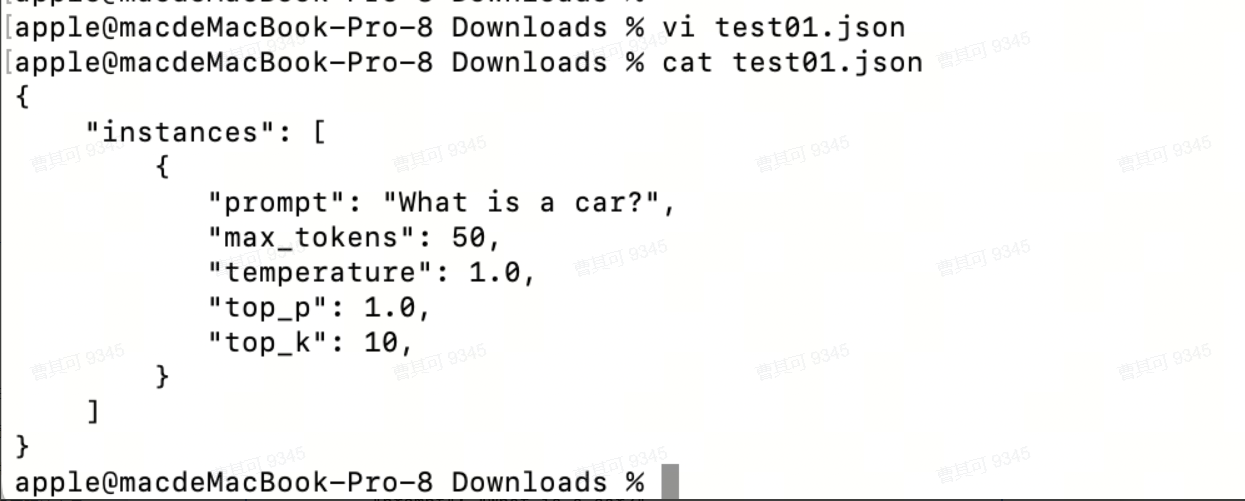
● 创建Mistral Json对象
{ "instances": [ { "instance_key_1": "value", ... }, ... ], "parameters": { "parameter_key_1": "value", ... }, ...}示例:
{"instances": [{"prompt": "What is a car?","max_tokens": 2000,"temperature": 1.0,"top_p": 1.0,"top_k": 10,}]}
● 请求调用
ENDPOINT_ID="3183347846178930688"PROJECT_ID="931354591844"INPUT_DATA_FILE="INPUT-JSON"curl \-X POST \-H "Authorization: Bearer $(gcloud auth print-access-token)" \-H "Content-Type: application/json" \https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/endpoints/${ENDPOINT_ID}:predict \-d "@${INPUT_DATA_FILE}"
示例:修改[INPUT-JSON]为当前文件
ENDPOINT_ID="3183347846178930688"PROJECT_ID="931354591844"INPUT_DATA_FILE="test01.json"curl \-X POST \-H "Authorization: Bearer $(gcloud auth print-access-token)" \-H "Content-Type: application/json" \https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/endpoints/${ENDPOINT_ID}:predict \-d "@${INPUT_DATA_FILE}"
输出:

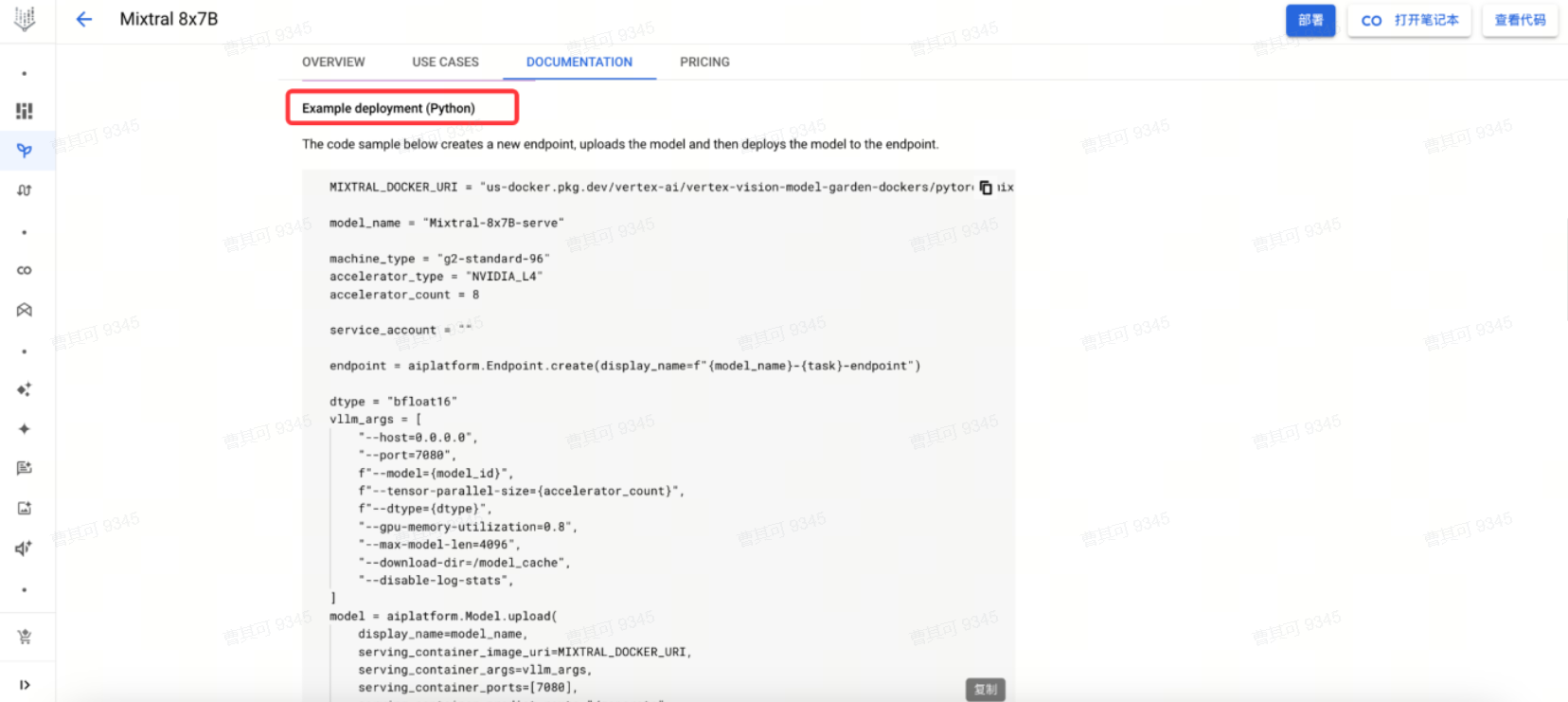
2. Python SDK方式
参考Example deployment。
至此,您即可使用在Google Cloud平台上使用Mistral模型。




