
Google Cloud Spanner | 超快速机器学习预测的必备套件
想在不编写和维护孤立的应用程序或移动数据的情况下进行超快速机器学习预测吗?只需使用 SQL 查询即可完成这一切,而且不必担心扩展、安全或性能。Google Cloud Spanner 是一个全球分布式且强一致性的数据库,它彻底改变了组织以透明和安全的方式存储和管理任何规模数据的方式。Vertex AI 改变了我们使用数据的方式,并利用机器学习、人工智能和生成性 AI 获取有意义的见解并做出明智的决策。Spanner 凭借其 Vertex AI 集成,可以帮助您使用部署在 Vertex AI 中的模型对事务数据进行预测,比以往任何时候都更容易、更快。
这意味着您可以消除单独访问 Cloud Spanner 数据和 Vertex AI 端点的需要。传统上,我们会从数据库中检索数据,并通过应用程序的不同模块或外部服务/功能将它传递给模型,然后将其提供给最终用户或写回数据库。现在,您不再需要使用应用程序层来组合这些结果,所有这些都可以在 Spanner 数据库中一步完成,就在您的数据所在的位置,使用熟悉的 SQL。
Spanner 与 Vertex AI 集成的优势包括:
改进的性能和更好的延迟:Spanner 直接与 Vertex AI 服务对话,消除了 Spanner 客户端和 Vertex AI 服务之间的额外往返。
更好的吞吐量/并行性:Spanner Vertex AI 集成在 Cloud Spanner 的分布式查询处理基础架构之上运行,该基础架构支持高度并行化的查询执行。
简单的用户体验:能够使用单一、简单、连贯和熟悉的SQL界面来促进Cloud Spanner规模上的数据转换和ML服务场景,降低了ML进入门槛,并允许更流畅的用户体验。
降低成本:Spanner Vertex AI 集成使用 Cloud Spanner 计算能力来合并 ML 计算和 SQL 查询执行的结果,从而无需配置额外的计算。
在本博客中,我们将探索使用 Vertex AI 中部署的模型从 Spanner 执行机器学习预测的步骤。这可以通过在 Spanner 中注册已部署到 Vertex AI 端点的 ML 模型来实现。
使用案例
为了实现这个功能,我们将使用我以前常用的电影观众评分预测用例,我们已经使用 Vertex AI 和 BQML 方法创建了该模型。电影评分模型根据各种因素(包括运行时间、类型、制作公司、导演、演员、成本等)在 1 到 10 的范围内预测电影的成功评分(换句话说,IMDB 评分)。创建此模型的步骤可作为代码实验室获得,并在本博客的下一部分提供链接。
先决条件
Google Cloud 项目:开始之前,请确保您已创建 Google Cloud 项目、启用计费、设置 Spanner 访问控制以访问已配置的 Vertex AI 端点,并启用必要的 API(BigQuery API、Vertex AI API、BigQuery Connection API)。
ML 模型:熟悉使用 Vertex AI Auto ML 或 BigQuery ML 的电影预测模型创建过程。
部署的 ML 模型:在 Vertex AI 端点中创建并部署电影分数预测模型。
实施此用例会产生相关成本。如果您想免费执行此操作,请使用 Vertex AI 中部署的 BQML 模型并为数据选择 Spanner 免费层实例。
开始执行
我们将使用使用 Vertex AI Auto ML 创建并部署在 Vertex AI 中的模型来预测 Cloud Spanner 中数据的电影成功分数。
以下是步骤:
第 1 步:创建 Spanner 实例
转到 Google Cloud 控制台,搜索 Spanner 并选择 Spanner 产品。
您可以创建实例或选择免费实例。
提供实例名称、ID、区域和标准配置详细信息。让我们选择与您的 Vertex / BigQuery 数据集相同的区域。就我而言,这是 us-central1。我们称这个实例为spanner-vertex。
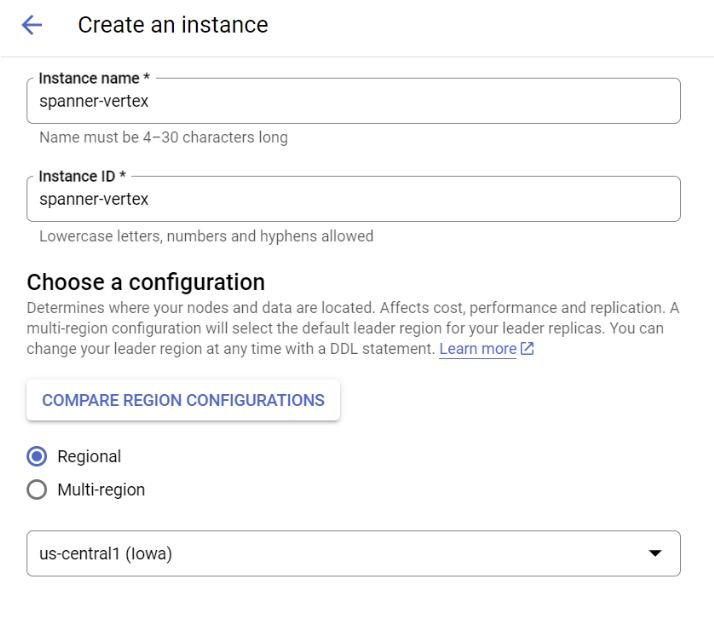
第 2 步:创建数据库
在实例页面中,您应该能够通过提供数据库名称和数据库方言(选择 Google 标准 SQL)来创建数据库。您还可以选择在那里创建一个表,但我们将其保留到下一步。继续并单击“创建”。
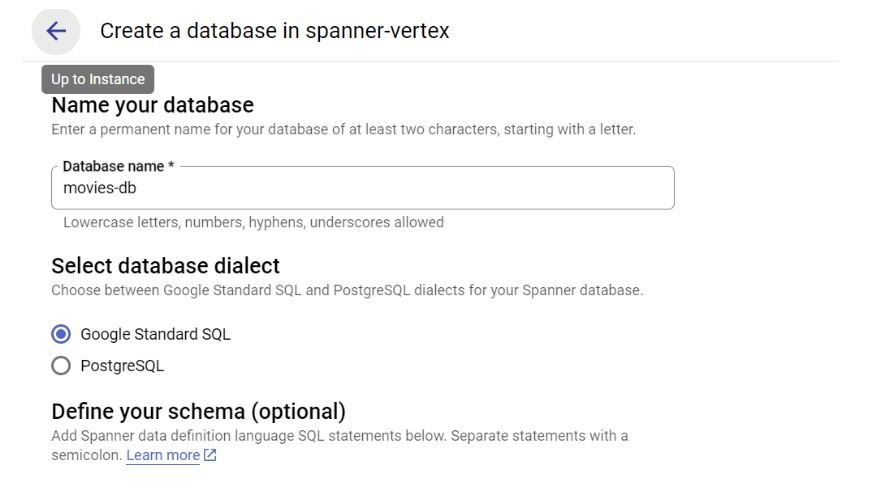
第 3 步:创建表
创建数据库后,导航至数据库概览页面。
单击 CREATE TABLE 按钮,将以下语句粘贴到 DDL TEMPLATES 部分并执行:
CRATE TABLE movies (id INT64,name STRING(100),rating STRING(50),genre STRING(50),year FLOAT64,released STRING(50),score FLOAT64,director STRING(100),writer STRING(100),star STRING(100),country STRING(50),budget FLOAT64,company STRING(100),runtime FLOAT64,data_cat STRING(10),) PRIMARY KEY (id);
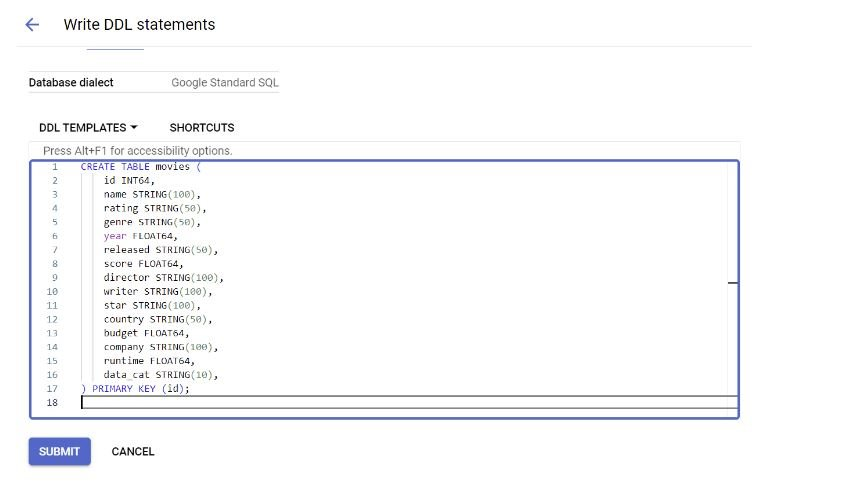
第4步:插入测试数据
现在我们已经创建了表,让我们在刚刚创建的表中插入一些记录以用作测试数据。
转到数据库概述页面,然后从可用表列表中单击“movies”。
在“表”页面中,单击左侧窗格中的 Spanner Studio,这将在右侧打开工作室。
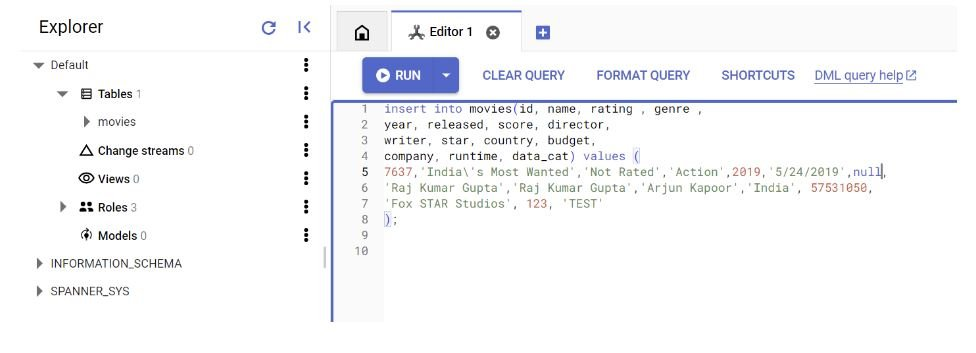
打开编辑器选项卡并运行以下语句来插入记录:
INSERT INTO movies (id, name, rating, genre, year, released, score, director, writer, star, country, budget, company, runtime, data_cat)VALUES (7637, 'India\'s Most Wanted', 'Not Rated', 'Action', 2019, '5/24/2019', null, 'Raj Kumar Gupta', 'Raj Kumar Gupta', 'Arjun Kapoor', 'India', 57531050, 'Fox STAR Studios', 123, 'TEST');
步骤 5:注册 Vertex AI AutoML 模型
您应该已经创建了分类/回归模型并将其部署在 Vertex AI 端点中(如先决条件部分中所述)。
如果您尚未创建用于预测电影成功率的分类模型,请参阅“先决条件”部分中的 Codelab 来创建模型。
现在模型已创建,让我们在 Spanner 中注册它,以便您可以将其用于您的应用程序。从编辑器选项卡运行以下语句:
CREATE OR REPLACE MODEL movies_score_modelREMOTE OPTIONS (endpoint = 'https://us-central1-aiplatform.googleapis.com/v1/projects/<your_project_id>/locations/us-central1/endpoints/<your_model_endpoint_id>');
将和替换为部署的 Vertex AI 模型端点中的值。您应该会看到模型创建步骤在几秒钟内完成。
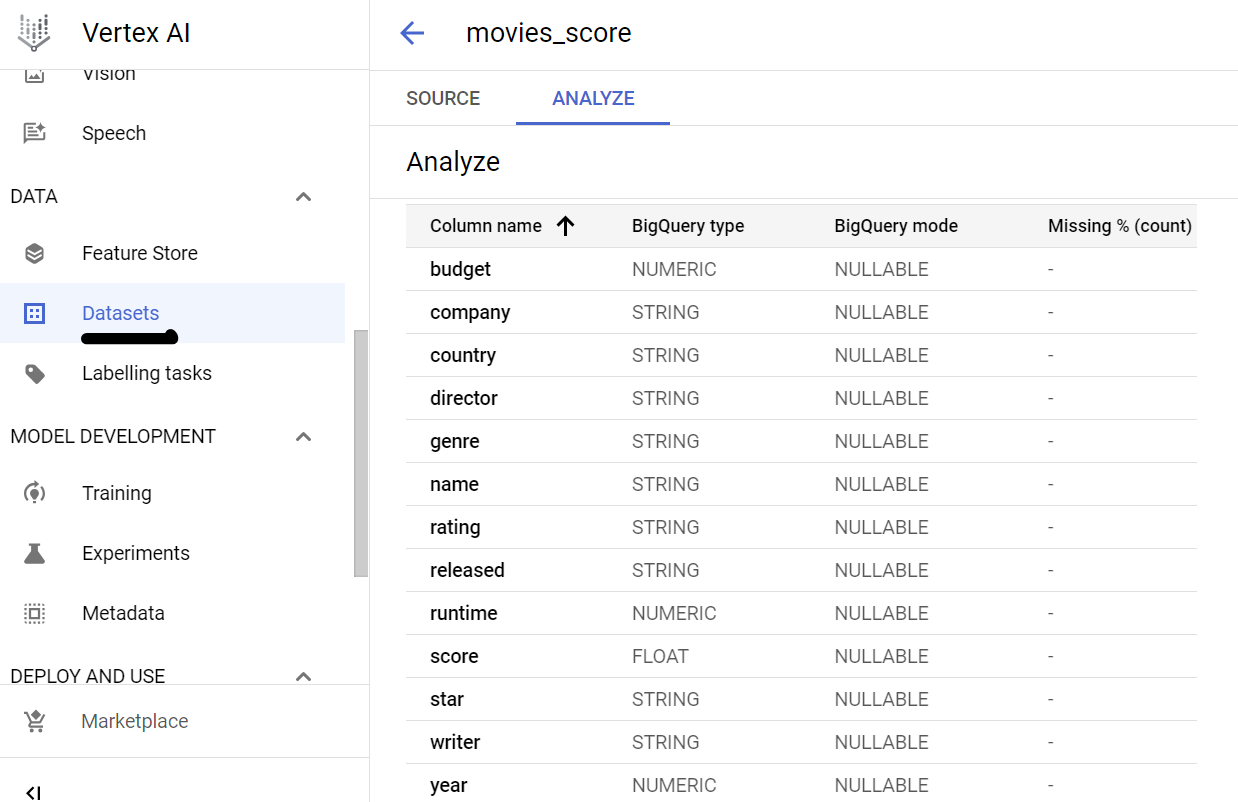
请注意,表和模型的架构结构应该匹配。在这种情况下,我在创建表时已经解决了这个问题,确保 DDL 中的字段和类型与 Vertex AI 中的模型数据集的架构匹配。请查看本博客中 DDL 的“步骤 3:创建表”部分。您可以导航到 Vertex AI 控制台中的“数据集”部分,然后单击您正在使用的模型的“分析”选项卡,根据 Vertex AI 中模型数据集的架构结构来验证这一点,如下图所示:
步骤 6:做出预测
现在剩下要做的就是使用我们刚刚在 Spanner 中注册的模型来预测我们插入到 movies 表中的测试电影数据的电影用户评分。
运行以下查询:
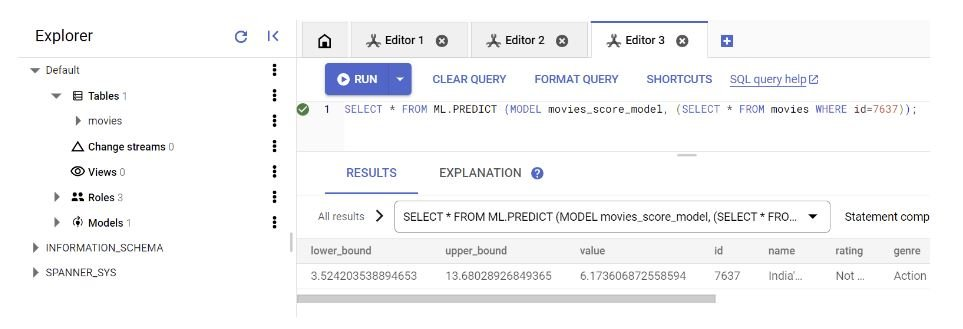
SELECT * FROM ML.PREDICT (MODEL movies_score_model, (SELECT * FROM movies WHERE id=7637));ML.PREDICT 是 Spanner 用于预测输入数据目标值的方法。该方法需要 2 个参数——模型名称和用于预测的输入数据。
在我们的例子中,子查询“select * from movie where data_cat = 'TEST'”会获取我们插入到 movie 表中进行预测的测试数据。
就是这样。您应该在测试数据的“值”字段中看到预测结果,如图所示:
' fill='%23FFFFFF'%3E%3Crect x='249' y='126' width='1' height='1'%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
步骤 7:将预测结果更新到 Spanner 表
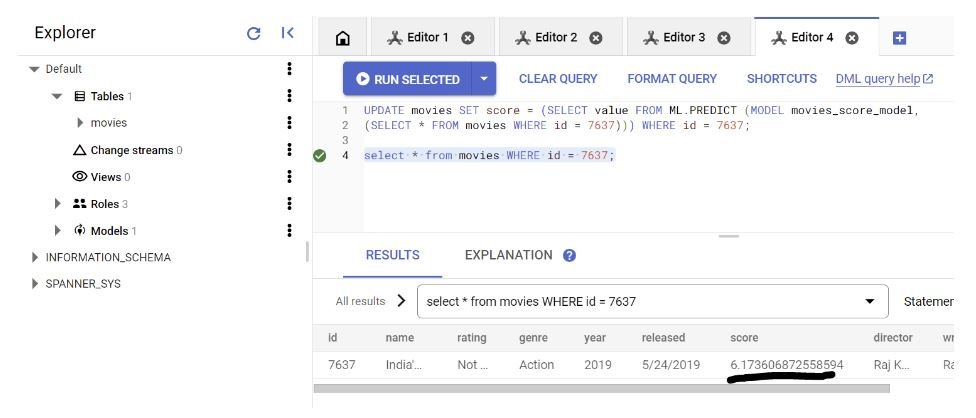
您可以选择将预测结果直接写入表中,这在您的应用程序需要实时目标更新时尤其有用。运行以下查询以在预测时更新结果:
更新电影设置分数= (SELECT value FROM ML.PREDICT (MODEL movies_score_model, (SELECT * FROM movies WHERE id = 7637))) WHERE id = 7637;
执行此操作后,您应该会在表中看到更新的预测分数。
结论
通过 Google Cloud Spanner 进行机器学习预测是将预测分析与数据库集成的强大方法。通过利用 Vertex AI 的功能和 Spanner 的灵活性,您可以增强实时应用程序中的决策。




